The debate over Hillary Clinton’s use of email reminds me of a Goldilocks’ tech management dilemma. Users tend to think you are running too slow or too fast, never just right:
Too slow
You face user ire, potential revolt, as IT (let alone security) becomes seen as the obstacle to progress. Users want access to get their job done faster, better, etc. so they push data to cloud and apps, bring in their own devices and run like they have no fear because trust is shifted into clever new service providers.
We all know that has been the dominant trend and anyone caught saying “blackberry is safer” is at risk of being kicked out of the cool technology clubs. Even more to the point you have many security thought leaders saying over and over to choose cloud and ipad because safer.
I mentioned this in a blog post in 2011 when the Apple iPad was magically “waived” through security assessments for USAID.
Today it seems ironic to look back at Hillary’s ire. We expect our progressive politicians to look for modernization opportunities and here is a perfect example:
Many U.S. Agency for International Development workers are using iPads–a fact that recently drew the ire of Secretary of State Hillary Clinton when she sat next to a USAID official on a plane, said Jerry Horton, chief information officer at USAID. Horton spoke April 7 at a cloud computing forum at the National Institute of Standards and Technology in Gaithersburg, Md.
Clinton wanted to know why a USAID official could have an iPad while State Department officials still can’t. The secret, apparently, lies in the extensive use of waivers. It’s “hard to dot all the Is and cross all the Ts,” Horton said, admitting that not all USAID networked devices are formally certified and accredited under Federal Information Security Management Act.
“We are not DHS. We are not DoD,” he said.
While the State Department requires high-risk cybersecurity, USAID’s requirements are much lower, said Horton. “And for what is high-security it better be on SIPR.”
Modernizing, innovating, asking for government to reform is a risky venture. At the time I don’t remember anyone saying Hillary was being too risky, or her ire was misplaced in asking for technology improvements. There was a distinct lack of critique heard, despite my blog post sitting in the top three search results on Google for weeks. If anything I heard the opposite, that the government should trust and catch up to Apple’s latest whatever.
Too fast
Now let’s look at the other perspective. Dump the old safe and trusted Blackberry so you can let users consume iPads like candy going out of style, and you face watching them stumble and fall on their diabetic face. Consumption of data is the goal and yet it also is the danger.
Without getting into too many of the weeds for the blame game, figuring out who is responsible for a disaster, it may be better to look at why there will be accidents/misunderstandings in a highly politicized environment.
What will help us make sure we avoid someone extracting data off SIPR/NIPR without realizing there is a “TS/SAP” classification incident ahead? I mean what if the majority of data in question pertain to a controversial program, let say for example drones in Pakistan, which may or may not be secret depending on one’s politics. Colin Powell gives us some insight to the problem:
…emails were discovered during a State Department review of the email practices of the past five secretaries of state. It found that Powell received two emails that were classified and that the “immediate staff” working for Rice received 10 emails that were classified.
The information was deemed either “secret” or “confidential,” according to the report, which was viewed by CNN.
In all the cases, however — as well as Clinton’s — the information was not marked “classified” at the time the emails were sent, according to State Department investigators.
Powell noted that point in a statement on Thursday.
“The State Department cannot now say they were classified then because they weren’t,” Powell said. “If the Department wishes to say a dozen years later they should have been classified that is an opinion of the Department that I do not share.”
“I have reviewed the messages and I do not see what makes them classified,” Powell said.
This classification game is at the heart of the issue. Reclassification happens. Aggregate classification of not secret data can make it secret. If we characterize it as a judgment flaw by only one person, or even three, we may be postponing the critical need to review where there are wider systemic issues in decision-making and tools.
To paraphrase the ever insightful Daniel Barth-Jones: smart people at the top of their political game who make mistakes aren’t “stupid”; we have to evaluate whether systems that don’t prevent mistakes by design are….
Just right
Assuming we agree want to go faster than “too slow”, and we do not to run ahead “too fast” into disasters…a middle ground needs to come into better focus.
Giving up “too slow” means a move away from blocking change. And I don’t mean achieving FISMA certification. That is seen as a tedious low bar for security rather than the right vehicle for helping push towards the top end. We need to take compliance seriously as a guide as we also embrace hypothesis, creative thinking, to tease out a reasonable compromise.
We’re still very early in the dinosaur days of classification technology, sitting all the way over by the slow end of the equation. I’ve researched solutions for years, seen some of the best engines in the world (Varonis, Olive), and it’s not yet looking great. We have many more tough problems to solve, leaving open a market ripe for innovation.
Note the disclaimer on Microsoft’s “Data Classification Toolkit”
Use of the Microsoft Data Classification Toolkit does not constitute advice from an auditor, accountant, attorney or other compliance professional, and does not guarantee fulfillment of your organization’s legal or compliance obligations. Conformance with these obligations requires input and interpretation by your organization’s compliance professionals.
Let me explain the problem by way of analogy, to be brief.
Cutting-edge research on robots focuses on predictive capabilities to enable driving off-road free from human control. A robot starts with near-field sensors, which gets them about 20 feet of vision ahead to avoid immediate danger. Then the robot needs to see much further to avoid danger altogether.
This really is the future of risk classification. The better your classification of risks, the better your predictive plan, and the less you have to make time-pressured disaster avoidance decisions. And of course being driver-less is a relative term. These automation systems still need human input.
In a DARPA LAGR Program video the narrator puts it simply:
A short-sighted robot makes poor decisions
Imagine longer-range vision algorithms that generate an “optimal path”, applied to massive amounts of data (different classes of email messages instead of trees and rocks in the great outdoors), dictating what you actually get to see.
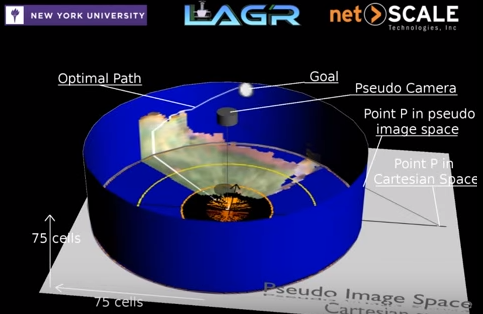
What I like about this optimal path illustration is the perpendicular alignment of two types of vision. The visible world is flat. And then there is the greater, optimal path theory, presented as a wall-like circle, easily queried without actually being “seen”. This is like putting your faith in a map because you can’t actually see all the way from San Francisco to New York.
The difference between the short and long highlights why any future of safe autonomous systems will depend on processing power of the end nodes, such that they can both create a larger areas of more “flat” rings as well as build out the “taller” optimal paths.
Here is where “personal” servers come into play. Power becomes a determinant of vision and autonomy. Personal investments often can increase processing power faster than government bureaucracy and depreciation schedules. I mean if the back-end system looks at the ground ahead and classifies as sand (unsafe to proceed), and the autonomous device does its own assessment on its own servers and decides it is looking at asphalt (safe for speed), who is right?
The better the predictive algorithms the taller the walls of vision into the future, and that begs for power and performance enhancements. Back to the start of this post, when IT isn’t providing users the kind of power they want for speed, we see users move their workloads towards BYOD and cloud. Classification becomes a power struggle, as forward-looking decisions depend on reliable data classification from an authoritative source.
If authoritative back-end services accidentally classify data safe and later reverse to unsafe (or vice-versa) the nodes/people depending on a classification service should not be the only target in an investigation of judgement error.
We can joke about how proper analysis always would chose a “just right” Goldilocks long-term path, yet in reality the debate is about building a high-performance data classification system that reduces her cost of error.