Let me explain the fundamental economics of a security industry in terms of Anthropic suddenly trying to run the American market.
- Security experts: help, snow has been falling too fast and it’s everywhere, we can’t even see.
- Anthropic: oh, scary, we are the only help you will need, because we’ve invented a velvet firehose. We will tell your board to pay us to dispense water faster than ever. Every drop will cost you.
The static analysis industry has spent the last two decades selling discovery as productivity. Coverity, Veracode, Checkmarx, Fortify, all built businesses on the same code quality proposition: scan to find a vulnerability, so you can expose bad software.
The proposition produced a blizzard of bugs and a lot of revenue. My friends and collegeaus got wealthy, very wealthy. And they did not quantitatively produce safer software. Edgescan’s 2025 Vulnerability Statistics Report finds that 45.4% of discovered vulnerabilities in large enterprises remain unpatched after twelve months. Veracode’s 2024 State of Software Security puts the average time to fix a critical flaw at 252 days, a 47% increase over five years. Two-thirds of organisations carry backlogs exceeding 100,000 findings.
Intelligence, as anyone who works in intelligence should tell you, doesn’t have a clear correlation to safety improvement. Our 419 fraud research proved intelligence in fact can generate overconfidence and therefore more risk. The constraints, in other words, was never the intelligence that generated detection numbers. The constraint was always the other end, our remediation throughput. Increasing confidence in detection might in fact lower quality of detection as well as fail to produce remediation benefits.
This is the long and established inheritance Anthropic walked into blindly, shooting from the hip at vulnerability researchers. The PR move it executed in April was elegant only in the way only weaponised our market failures. Like a bull in a China shop is elegant.
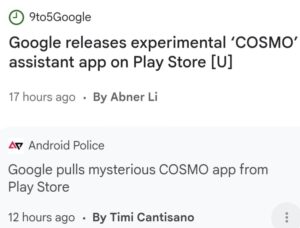
I’ll lay it out here, pulling together a month of research revealing Mythos is not what it’s being billed as. On 7 April 2026, Anthropic announced Project Glasswing and Claude Mythos Preview. The framing was immediately suspicious and unvetted. Mythos found a 27-year-old vulnerability in OpenBSD and a 16-year-old bug in FFmpeg. It found privilege escalation chains in the Linux kernel.
To me this reads like Tesla in 2016 saying they’ve landed driverless capability, call the press, just because they drove a straight line on an empty well-marked highway in the desert. Yeah, that’s not what the expert sees at all, but someone who knows nothing about AI might scream with joy and say take my money.
The model was being pitched heavily, by Anthropic’s account, “capable of identifying and then exploiting zero-day vulnerabilities in every major operating system and every major web browser.” The capability therefore was plumped all the way up into being too dangerous for general release. Access was gated like a Long Island bar mitzvah, only through a consortium of the partners with the most money and least incentive to scrutinize the claims. Microsoft, Apple, Google, Amazon Web Services, JPMorgan Chase, Nvidia.
It’s like announcing the Pediatricians Association will be gifted the first driverless Tesla to judge the technology as safe for humanity. In 2016 I sat with other researchers and tore apart the Tesla driverless claims. We proved it would kill, that it failed basic safety, that the demos were highway theater. Nobody cared enough to stop Tesla.
Musk accused the people pointing out his lies of being responsible for the deaths he caused. Proof of danger was criminalized. Tesla started killing people. Mythos is the same backwards gating pattern again. Pick the audience least equipped to challenge the claim and the most susceptible to fraud, hand them the keys, call the tragic results validation.
Read the Anthropic circular-reasoning disclosures carefully. Discovery capability is asserted. Evidence sits behind extremely wealthy and privileged partnership gates. Public verification becomes irresponsible by definition, because public verification means publishing the exploits that prove the horseshit. The model is positioned as so capable that scrutinising the capability claim is itself the threat.
Anthropic is running the reverse logic on static analysis pitches. Coverity sold code scanning as a productivity gain. Mythos sells that same scanning as civilisational menace requiring prayers and wishes to stop it. Same activity. Same throughput problem on the back end. Completely opposite affect on the front end. The vendor who could not solve a remediation gap has rebranded that gap as the threat, and then sells frontier access.
The asymmetry is the whole story. If frontier AI was actually good at finding exploits, it would be great at preventing them. Point it at code, remove the bugs faster than anyone could discover them, ship safer software, migrate off legacy systems at speed. That world is not the one Anthropic is selling. The company that cannot demonstrate defensive throughput sells offensive capability instead. The thing the model fails at gets buried. The thing the model is claimed to do gets gated behind a consortium that cannot publish its results. The danger frame is the cover for the generation-quality failure underneath.
The discipline imposed on the previous generation of dumping rough exploits on the market was procurement. Coverity had to publish detection rates. Synopsys had to demonstrate false positive ratios. Semgrep, SonarQube, Fortify, all submitted to OWASP Benchmark scoring, however gamed. CISOs demanded numbers because budgets demanded numbers. The capability claims of discovery vendors were bounded by buyers who could walk away and compare apples.
Mythos tries to jump outside that discipline. Bruce Schneier signed onto the alarm early, putting his name on the CSA “Mythos-Ready” paper with former CISA and NSA leadership. On April 13 he defended Mythos exclusivity by dismissing the AISLE small-model result as likely to drown in false positives. Two weeks later, perhaps as a mea culpa after being exposed for the bad math, he flagged the bad math himself: nobody knows the false positive rate on unfiltered output. He co-wrote a piece in IEEE Spectrum pivoting to “incremental step” and shifting baseline syndrome. Smart people doubling down on the wrong call is the 419 pattern. Intelligence fuels a Schneier engine running wrong with overconfidence, not any guard against it.
Why did the industry react more cautiously so late? The giant 250-page technical document was an immediate clue because it published hyperbolic adjectives where the industry standard would be a confusion matrix. Seven pages had actual useful content. The rest was saying Anthropic trades on noise. Sophisticated. Concerning. Capable. The vocabulary of unfalsifiability deployed exactly where our usual science of measurement was supposed to expose the failure modes.
The buyer also changed. Coverity was run through a CISO paid to put their reputation on the residual risks. Mythos convinces a board that their drop of rain in a hurricane is the only one that is really wet. The evidence standard collapses when the procurement process becomes a Boogeyman in a non-technical national security conversation. The price ceiling lifts all the way to “a malware caravan is coming to take your women and children” of the great McAfee disaster. Protip: McAfee lied to make money and national security wonks who listened to him set back the industry decades. The Alan Turing Institute’s CETAS report notes Mythos Preview costs five times Opus 4.6. Frontier safety theatre commands frontier safety pricing like a forever bloating McAfee denylist.
I always come back to the fact that Anthropic did not release a benchmark on discovery or exploit, while blurring discovery and exploitability in their announcements. They confidently believed their own lies, I suspect, like we found among the most intelligent 419 fraud victims. Stanislav Fort and the AISLE team ran the test that Anthropic chose not to do, or publish. They isolated specific vulnerabilities Mythos had showcased and ran the same code through small, cheap, open-weight models. Eight out of eight detected the flagship FreeBSD exploit, including a 3.6-billion-parameter model costing a dime per million tokens. One dime. Think about that discovery number on the CISO desk. A 5.1-billion-parameter open model recovered the 27-year-old OpenBSD chain. Independent measurement generated huge pressure on Anthropic and they squeaked out a response that they really meant exploit only. The capability is wide and broadly accessible. Anthropic’s framing required it to be extremely narrow and exclusive.
OpenBSD itself is the cleanest counterexample to the Mythos framing. A 27-year-old bug got disclosed, a small patch shipped, the project moved on because it’s a day of the week that ends in y. Privilege separation, pledge, unveil, default-deny. Architecture did the work and not any AI discovery. The fix was a few lines, which is exactly the work that AI should have done instead of claiming the world is about to be harmed. Drilling holes in ships just to charge admission to bailing crews that arrive is not a good business model.
Peter Swire, the Georgia Tech professor and former Clinton and Obama administration adviser, told Scientific American that “a large fraction of the cybersecurity professors believe this is pretty much what was expected, and pretty much more of the same.” Ciaran Martin, former chief of the UK National Cyber Security Centre, agreed.
The capability is real. Computers are real. The framing is theatre. AI has been killing people for over a decade already and I see exactly zero headlines about putting Elon Musk in jail, his rushed-to-market AI banned from doing further public harms.
If driverless could reduce crashes, it would show up in the data. The opposite is true, and crashes increase around driverless. If frontier models could write secure code at scale, the rational response to a 27-year-old OpenBSD bug would be rapid remediation and even migration. Find the bug, generate and deploy the fix. The bottleneck would be discovery turning into remediation, and Mythos would be the easy answer to it.
The empirical record on AI code generation is the actual story. Pearce and colleagues at NYU and Stanford found 40% of Copilot output contained vulnerabilities mapped to known CWE classes. Veracode’s multi-LLM benchmark in Java, Python, C# and JavaScript reported a 45% security test failure rate, with 86% failure against cross-site scripting. Tihanyi and colleagues ran 330,000 C programs through multiple LLMs and found 62% contained at least one vulnerability. Apiiro’s June 2025 production data showed AI-assisted developers shipping three to four times more code and ten times more security findings. Over 10,000 new findings per month, just from AI-generated code.
More AI code means more bugs, faster. That disproves both Anthropic claims to find bugs faster (false positives, over-confidence and fabrication) and claims to generate safe code faster.
This is what makes the Mythos framing so disappointing.
The same model class that cannot be trusted to write safe code is credited with understanding code well enough to weaponise it. The asymmetry is damning, not scary. Anthropic gets credit for offensive capability while remaining silent on defensive throughput, because publishing a generation-quality benchmark would expose that the discovery-capability has nothing measurable behind it.
The static analysis industry drew attention to a backlog explosion many years ago. Two decades of discovery without remediation throughput produced 100,000-finding queues at most large organisations. I remember one day a long time ago staring at 60,000 tickets full of medium and above vulns to map a bailout. We needed a steam engine and a pump. We got buckets and a few hands to carry them. Bitsight’s longitudinal data puts the typical compound monthly remediation rate at 5%. Semgrep’s 50,000-repository study shows findings open more than 90 days become unlikely to ever be fixed. I’ve seen it all.
A frontier model that scans continuously and generates findings at ten times the rate is like bringing a red velvet firehose to a blizzard. It accelerates the wrong direction for a fee. Gartner analysts told InformationWeek that less than 1% of potential vulnerabilities Mythos surfaces have been fully patched. Over 99% remain open.
The Anthropic argument is probably made circular by design, given how the ivory tower minds of Silicon Valley tend to think now. Mythos finds bugs. Maintainers cannot patch them fast enough. Therefore the world needs more Mythos. More, more, more and never satisfied but some small group of people got rich on it and bought an island far away from the disasters they produced.