30 April 2026, 16:33:37 UTC. Canonical’s incident monitoring system marks blog.ubuntu.com as Service Down.
Within ten minutes the rest of the company’s public web was down as well: the main site ubuntu.com, the security advisory APIs that downstream package management depends on, the developer portal, the corporate site, the training platform. These disruptions ran for roughly twenty hours.
1 May 2026, 12:44 UTC. Service Restored.
The group claiming responsibility for the attack said it used a paid service. They named one tool they had rented: a commercial denial-of-service product called Beamed, sold under multiple TLDs, with beamed.su serving as the marketing and blog site and beamed.st serving as the customer login portal. The April 2026 blog post “How to Bypass Cloudflare with Advanced Stresser Methods” advertises three named techniques for defeating Cloudflare protection, including residential IP rotation and manual “endpoint hunting” to locate origin servers. Beamed is explicit about what it sells:
Cloudflare acts as a reverse proxy, hiding the origin server’s IP address. Many low-quality booters fail against “Under Attack Mode” or Bot Fight Mode. Beamed.su employs several advanced techniques to effectively stress test websites protected by Cloudflare and similar CDNs.
The blog post hosting this paragraph is itself served by Cloudflare. The product sold is Cloudflare bypass. The hosting provider for the seller is Cloudflare.
A week after the attack, beamed.su and beamed.st remain online. Both resolve to Cloudflare AS13335 addresses. Canonical’s two repository endpoints, security.ubuntu.com and archive.ubuntu.com, also resolve to Cloudflare AS13335 addresses, as a paid customer relationship.
Cloudflare fronts attackers for free and bills the victims for relief.
The question I repeatedly have been asked is whether what just happened amounts to blackmail, and how the actor that claimed responsibility (a self-described pro-Iranian group calling itself the Islamic Cyber Resistance in Iraq, also styled as 313 Team) ends up renting attack capacity from a service whose front-end infrastructure is operated by the same company that Canonical eventually paid for relief.
Beamed’s consumer-facing domains are registered through a registrar called Immaterialism Limited, which sells domain registration on a flat-rate basis and via a JSON API. Cheap, automated registration with zero friction is typically associated with abuse hosting. Immateriali.sm is itself proxied through Cloudflare nameservers (tani.ns.cloudflare.com and trey.ns.cloudflare.com).
Immaterialism Limited is registered at Companies House in the United Kingdom under company number 15738452. It was incorporated on 24 May 2024 with one director, Nicole Priscila Fernandez Chaves of Costa Rica (date of birth March 1993), at a mass-mailbox address on Great Portland Street in London.
On 11 April 2025 Fernandez Chaves resigned the directorship while retaining 75 percent or more of the economic interest. The replacement director was Naomi Susan Colvin, a British national resident in England, appointed at the same address.
Colvin is the former Director of the Courage Foundation, the legal-defence vehicle whose trustees have included Julian Assange, John Pilger, Vivienne Westwood, and Renata Avila, and which has supported beneficiaries including WikiLeaks and Barrett Brown. Her current role is UK and Ireland Programme Director at Blueprint for Free Speech, working on whistleblower protection and anti-SLAPP litigation. The legal campaign that prevented the extradition of Lauri Love to the United States ran under her direction. She is a longstanding activist.
On 26 February 2026 Immaterialism Limited filed two changes at Companies House on the same day: a registered office change (from 85 Great Portland Street to 167-169 Great Portland Street) and a change of details for Fernandez Chaves as person with significant control.
The next day, 27 February 2026, the routing infrastructure that announces Beamed’s IP space and that of related services moved jurisdiction.
The autonomous system that announces Materialism’s address space is AS39287. RIPE allocated this AS number on 24 January 2006. Its routing identity has been preserved continuously since then, but its registered operator and the country of record have changed twice.
From around 2017 to roughly 2020, AS39287 was held by Privactually Ltd, a Cypriot company, and operated under the name FLATTR-AS. Flattr was the micropayments project of Peter Sunde Kolmosoppi, one of the founders of The Pirate Bay. The abuse contact for prefixes under that registration was abuse@shelter.st.
From 2020 to 2026, the same AS number was reassigned to ab stract ltd, a Finnish company at Urho Kekkosen katu 4-6E in Helsinki. Its maintainer object on the RIPE record was BKP-MNT. Named person of record: Peter Kolmisoppi (handle “brokep”), another founder of The Pirate Bay, with a Malmö postal address and the email noc@brokep.com. The authoritative nameservers for the operator’s domain abstract.fi were the three Njalla nameservers at njalla.fo, njalla.no, and njalla.in. Njalla is the privacy-as-a-service domain proxy founded by Peter Sunde and operated through 1337 Services LLC in St. Kitts and Nevis. Some prefixes under ab stract carried abuse contacts at cyberdyne.is.
Reassignment on 27 February
On 27 February 2026, at 12:11:48 UTC, RIPE recorded the third reassignment. AS39287 became the property of Materialism s.r.l., a Romanian company at Bulevardul Metalurgiei in Bucharest, operating under the name “materialism.” A Materialism RIPE membership had been provisioned five months earlier, on 30 September 2024, and had then sat dormant. The reassignment included the IPv4 prefix 45.158.116.0/22 and the IPv6 prefixes 2001:67c:2354::/48 and 2a02:6f8::/32, the last of which was originally allocated in August 2008 under the prior regime.
The peering arrangements were preserved across all three transitions. AS39287 has continued to import from and export to AS42708 (Telia), AS37560 (GTT), AS12552 (GlobalConnect), AS34244 (Voxility), and AS54990, in identical configuration, from the FLATTR period to the materialism period. The same routes leave the same upstream networks. The visible operator name is the variable.
The IANA list of accredited domain registrars also shows that the customer base of Immateriali.sm includes 1337 Services LLC, the trading entity behind Njalla. The registrar end of the chain and the privacy-proxy end are accordingly under the same alumni cluster.
1337 Services. Yeah, I know.
Cert rotation on 27 February
The relevant certificate transparency record for Canonical’s repository endpoints shows the following entries during the same 24-hour window in which the routing reassignment occurred.
At 06:14:03 UTC on 27 February, Let’s Encrypt issued a fresh apex certificate for archive.ubuntu.com.
At 19:13:35 UTC on the same day, Let’s Encrypt issued a fresh apex certificate for security.ubuntu.com. The 2026 certificate transparency record for that hostname before this entry contains regional mirror certificates only. An apex certificate at security.ubuntu.com does not appear earlier in the visible log.
At 22:14:03 UTC on the same day, a fresh certificate was issued for clouds.archive.ubuntu.com.
In the following nine days the same pattern repeated for azure.archive.ubuntu.com, wildcard-gce.archive.ubuntu.com, and wildcard-ec2.archive.ubuntu.com. Each new certificate was issued for the apex hostname rather than for a regional mirror.
A valid origin certificate on the apex hostname is a precondition for putting that hostname behind a content delivery network without breaking encryption between the network and the origin. The certificate has to exist at the origin before the network can be told to fetch from there.
The synchrony of these two events on 27 February has not yet been explained.
The Attack Timeline
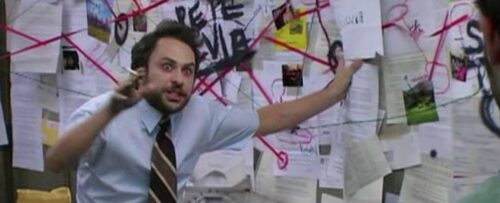
The minute-by-minute log of the incident is taken from Canonical’s own status.canonical.com page, snapshotted into Ubuntu Discourse thread 81470 by a user at approximately 22:52 UTC on 30 April. All times below are UTC. Where original sources used Pacific Daylight Time or British Summer Time, conversion is given inline.
- 16:33:37: blog.ubuntu.com first marked Down. Recorded as the Incident Start Time.
- 16:34:10: canonical.com Down.
- 16:34:45: academy.canonical.com Down.
- 16:35:15: developer.ubuntu.com Down.
- 16:35:22: maas.io Down.
- 16:36:09: jaas.ai Down. Ubuntu Security API (CVEs) Down.
- 16:37:13: Ubuntu Security API (Notices) Down.
- 16:41:57: assets.ubuntu.com Down.
- 16:43:25: ubuntu.com Down.
So the security advisory feed went dark within three minutes of the start, and the marketing apex within ten. The two hosts that were not yet attacked at this point were security.ubuntu.com and archive.ubuntu.com, the two endpoints whose unavailability breaks apt update on every Ubuntu installation worldwide.
- 19:34:38: security.ubuntu.com first marked Down.
- 19:40:01: archive.ubuntu.com Down.
This is notable to me because an attacker held the repository endpoints in reserve for three hours, and then activated them late.
From 19:40 UTC for the next seventy minutes, both repository endpoints flapped repeatedly between Down and Operational on the status board. The status log records five Down/Operational transitions on security.ubuntu.com and four on archive.ubuntu.com during that period.
This pattern is consistent with a mitigation being attempted at the origin (rate limits, geographic filters, traffic scrubbing) and failing under sustained load at the announced 3.5 Tbps scale.
- 20:50:29: archive.ubuntu.com marked Operational.
- 20:51:13: security.ubuntu.com marked Operational.
After this 44-second window neither host appears Down again in the captured snapshot, which extends to 22:52 UTC. The flapping stops cleanly. The two endpoints stabilise together, less than a minute apart, four hours and seventeen minutes into the attack.
The currently resolved state of those two hostnames matches the destination implied by that stabilisation. As of this writing, security.ubuntu.com and archive.ubuntu.com both resolve to 104.20.28.246 and 172.66.152.176, which are addresses now being operated by Cloudflare under AS13335.
The other affected hosts (ubuntu.com, canonical.com, launchpad.net, snapcraft.io, login.ubuntu.com) all still resolve to Canonical’s own AS41231 space at 185.125.189.x and 185.125.190.x. The authoritative nameservers for ubuntu.com remain ns1.canonical.com, ns2.canonical.com, and ns3.canonical.com.
The selective Cloudflare onboarding
Canonical handed Cloudflare exactly two A records: the two records the attacker had targeted for repository denial. Everything else stayed on Canonical’s iron and weathered the attack under whatever mitigation was already in place.
The non-repository hosts continued flapping through the end of the snapshot. They eventually came back through some combination of upstream filtering and the attack subsiding.
Canonical’s first public acknowledgement was posted at 07:13 UTC on 1 May, ten hours after the repository endpoints had been made stable behind Cloudflare. Full restoration of all components was confirmed at 12:44 UTC on 1 May, roughly twenty hours after onset.
Naming what happened
No ransom payment moved by any visible channel.
Cryptocurrency flows of the relevant magnitude are absent from the public record.
A demand letter has not surfaced.
Negotiation, if any occurred, was conducted in private.
What did move was a paid subscription.
Canonical’s two highest-value endpoints, the ones whose denial creates a worldwide failure of automated security updates, transitioned to a service relationship with a vendor whose other current customers include the booter operation that was attacking them.
This transaction concluded without requiring Cloudflare to issue any demand. Beamed’s continued availability for hire is the demand. The outage clock running on Canonical’s own infrastructure is the deadline. The protector collects on both sides while remaining, at every individual moment, content-neutral and within the letter of its terms of service. Whether Cloudflare designed this position or arrived at it through the aggregation of unrelated customer decisions is, from the perspective of how a racket operates, immaterial. It works the same either way.
Any historian should be able to call this out as the same architecture we’ve all seen before.
Moses Annenberg’s General News Bureau in the 1930s sold timely race-track results to bookmakers across the United States. Bookmakers who subscribed survived. Bookmakers who declined the subscription found their odds-setting capacity destroyed by competitors who had subscribed.
Annenberg’s revenue depended on his monopoly over the verification of race results, which made every unauthorised bookmaker dependent on his wire to operate. The federal government broke that monopoly through tax prosecution in 1939, and successor wire services were raided into the 1940s. Mayor LaGuardia in 1942 wasn’t messing around:
Nine men were arrested yesterday in raids on a fifth-floor suite of offices at 126 Liberty Street and in apartments in an eighty-five-family house at 834 Penfield Street, the Bronx, in what the police called a “million-dollar-a-year wire service for poolroom bookmakers and other gamblers on horse racing in New York, New Jersey, Westchester and Nassau County.”
The DDOS-protection market reads today as roughly the same position with respect to the booter market. Cloudflare’s revenue depends on its position as the verifier of whether a service is reachable on the public internet. When the same company is also the booter’s hosting provider, the threat and protection roles have been merged into a single revenue stream.
What distinguishes this particular incident is how the public record appears to be laundered. Companies House holds the corporate paperwork. RIPE’s database holds the routing reassignment. Certificate transparency logs capture the rotation date for the apex certificates. Canonical’s own status page captures the minute the records changed.
Every part of it is the public registry or a corporate disclosure. Even the 27 February cluster is on the public record. On that day three preparations completed within a single calendar window. Materialism s.r.l. took ownership of AS39287 and the long-held IPv6 prefix that came with it. Immaterialism Limited filed its Companies House paperwork. And on Canonical’s side, the two apex hostnames that would later be moved behind a content delivery network had their origin certificates renewed.
The four-hour gap between the onset of the attack and the appearance of Cloudflare addresses on Canonical’s repository hostnames is the interval during which the purchasing decision moved. I imagine engineers moving from “hold the line” against attacks routed through Cloudflare to “sign the Cloudflare contract.” Roughly the time it took for the cost of continued outage to exceed the deal Cloudflare offered.
The new customer relationship was visible at 20:50:29 UTC on 30 April 2026.