
As I read a new paper about the effects of AI, I couldn’t help but notice the authors stumbled onto a clean withdrawal demonstration and could not see it because the field rewards sensationalist “AI assistance reduces persistence“. 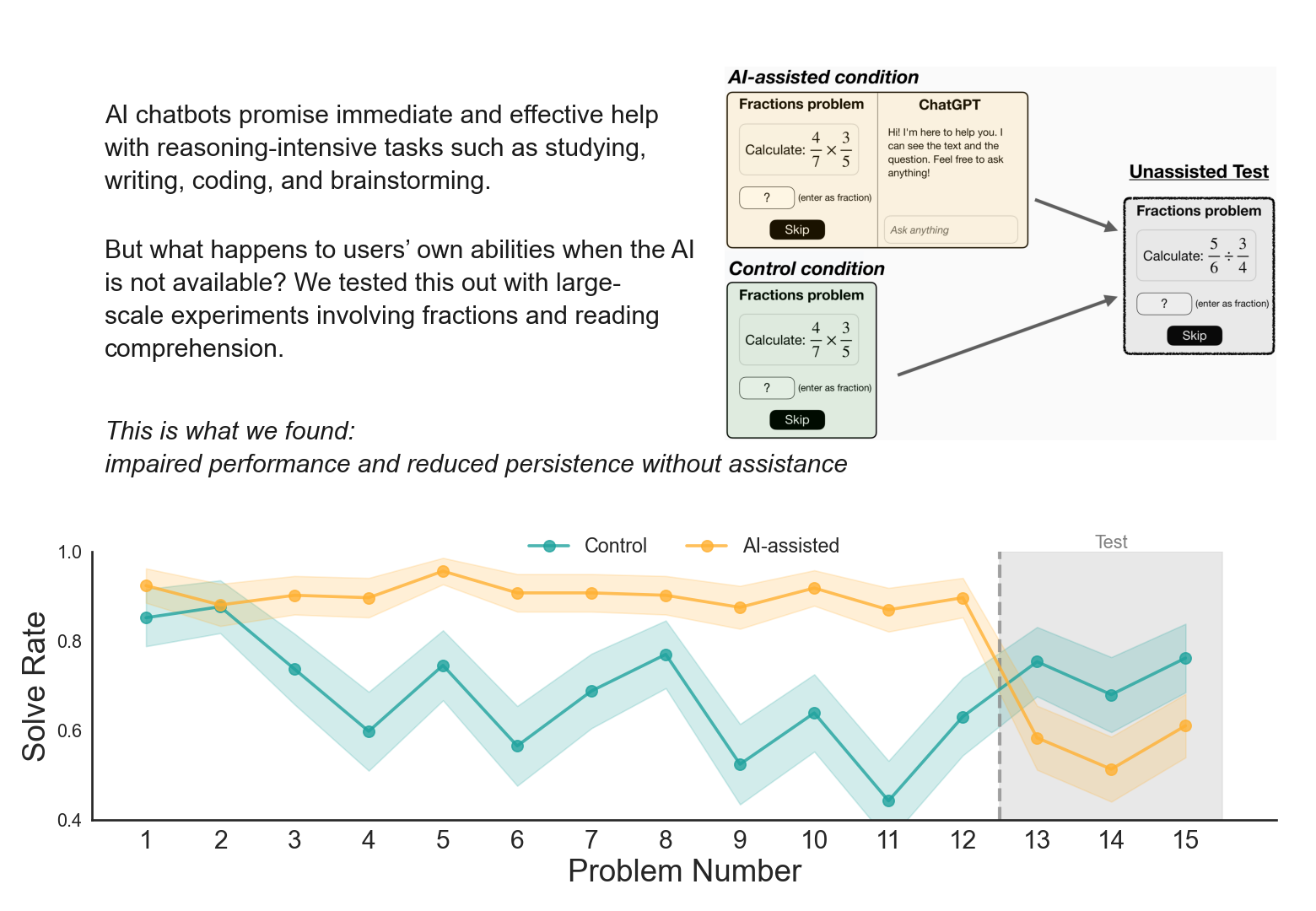
That is the kind of “novel” framing that gets you into Nature Human Behaviour or the equivalent. Saying something more authentic like “brief variable-reinforcement exposure produces measurable extinction-phase behavior” gets you into a time-machine for a 1970s journal nobody reads. Same data, totally different career path.
Let’s look carefully at the premise the entire paper is built upon. They have a designed experiment that administers a reliable hit of an engineered substance for ten minutes, then yanks it. The reliable hit is not “AI” in any general sense. It is an answer-vending machine pre-loaded with the solution, instructed to greet warmly, available on every problem.
The participant types a single word and receives a correct answer. That is not assistance. That is reinforcement delivery on a fixed-ratio schedule with one hundred percent reliability, which is the cleanest possible conditioning protocol short of direct electrode stimulation.
Bzzzt. Bzzzt. Bzzzt.
Then withdrawal. No taper, no warning, no transition. The instrument reliably answering every query for ten minutes evaporates. Now the participant is asked to perform on three problems while the experimenters measure the gap. The gap is real. The gap is also exactly what any conditioning protocol produces at the moment of extinction. Calling it “impaired independent performance” frames the post-withdrawal state as the true measure of capacity, when it is the measure of the withdrawal itself. The participant’s actual capacity was visible before the conditioning began. In Experiment 2’s pretest, the eventual direct-answer subgroup, the hints subgroup, the didn’t-use-AI subgroup, and the control group were statistically indistinguishable on both solve rate and skip rate.
This is cruel.
The IRB approved this as low-risk because the tasks are “short cognitive exercises” and nobody got hurt. By the standard ethical frame of physical harm, that is true. By the frame of what was actually done, the participants were placed in a brief but real conditioning-and-withdrawal cycle, told their performance was being measured, and then had their post-withdrawal behavior reported as evidence of cognitive damage they sustained from a technology.
The participants were told the AI was there to help them work through problems. They were not told the AI had been pre-loaded with the answer key for every problem they would see. That is the manipulation the entire effect rests on, and it was concealed from the subjects.
The mechanism the authors propose in the conclusion, hedonic adaptation on effort reference points, is correct and undermines their own framing.
Reference-point shifting under reliable access is the formal description of dependence formation. If a ten-minute exposure shifts the reference point measurably, what they have demonstrated is the speed of dependence onset under engineered conditions, not a property of AI use in the wild where access is intermittent, the assistant is not pre-loaded with answers, the responses are variable in quality, and no experimenter is about to remove the tool mid-task while measuring you.
There is a real phenomenon to study, if you use some common sense. Endoscopists whose unaided detection rates drop after months of routine AI-assisted colonoscopy, which is the Budzyń study the authors cite. Surgeons whose unaided technique degrades after years of robotic assistance. Pilots whose manual flying skills atrophy under decades of autopilot dependence. Those settings involve sustained exposure over months or years, naturalistic conditions, and outcomes that matter. A ten-minute Prolific session with a primed bot is not that. It is an analog model so simplified that it represents an unfair representation.
What the paper is actually giving us is the within-subject pretest-to-test panel for the direct-answer subgroup, which shows that conditioning a person to expect immediate answers and then removing the source produces a measurable behavioral shift relative to where that person started ten minutes earlier.
No shit.
That is a withdrawal study finding.
If you admit what’s really going on and read it as a withdrawal study finding, it is interesting and consistent with eighty years of such operant literature. Got it, nothing novel here.
However, read as the title wants you to read it, there is huge overreach dressed in causal-RCT vocabulary. I’m no fan of the institutional affiliations, precisely because they are the kind of “authority” appeal that will bleed this nonsense into policy discussions where the methodological failures will not be sufficiently exposed.

