Several people have asked what I thought when Jürgen Geuter, writing as tante, argued that AI is a fascist artifact.
He’s not saying AI is being deployed badly. He’s saying AI is inherently fascist. He places it in the category Langdon Winner reserved for technologies that demand a particular social order, the way the atom bomb demands a centralized command state. You cannot run that particular bomb democratically. In that sense, tante wants the model in the same classification.
I get it. I typically talk about minefields or cluster bombs as inhumane, and therefore a crime. If we can classify a weapon off limits, we can feel comfortable saying it crosses a bright line.
The problem for me is how his argument refutes itself.
He leans on Stafford Beer’s maxim that the purpose of a system is what it does. As such, tante reads the purpose of AI off its most disgusting and reprehensible deployments. Palantir, an overtly fascist company out to destroy democracy, markets its software as a weapon for kill decisions. Andreessen, a mockery of itself, demands the right to build without regulation while also demanding regulations that erase its critics. Image models inherit the racism of the data scraped to train them. These deployments are all good examples of the bad, and they are reactionary.
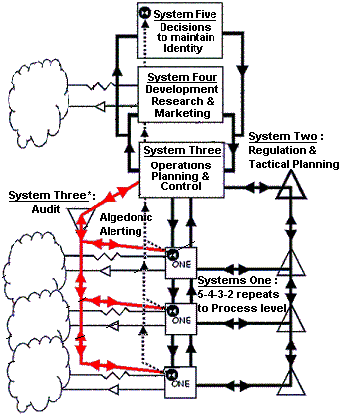
The lean into Beer comes from tante saying he is an admirer. Beer built Project Cybersyn, a centralized computer system meant to coordinate the nationalized economy of Allende’s Chile.
Stafford Beer’s VSM (Viable System Model)
That’s interesting because it’s in the similar class as the bad examples above. Centralized computational coordination of an economy. By tante’s own logic a system is whatever it does, so Cybersyn was socialist because it served socialism. The politics are defined by the person in control and to what end they are aiming.
Record scratch.
This is the applied, contingent politics tante insists does not exist. He cannot endorse the principle that a system is what it does and condemn the model class as fascism in the same breath. That principle is what makes Cybersyn liberatory, and it puts the politics in the operator of the system.
Going back to Winner instead, we should separate two kinds of political technology. For example, when Robert Moses built overpasses so low that large buses carrying poor families could not reach the beach, that was politics by design.
Jones Beach was made inaccessible by bus due to the intentionally low overpasses, like this one. Source: Pin-Up
The bomb is different from the overpass. Its politics are in the functional necessity. In other words, the evidence tante uses is all about the overpass. The frontier vendors would concentrate power because of how it is financed and owned, not because a working model can only exist in a form that prevents poor families from going to the beach.
On that point, we have evidence of models that pass the test. Apertus, from ETH Zurich and EPFL, was pretrained from scratch on rights-clean data. Pleias built its models on the Common Corpus the same way. Run the weights locally through Ollama with no telemetry and no API, and the capability should be free of fascism. And this trend seems like common sense. The model does not need its lab, while the bomb always and still needs the state.
M28/M29 Davy Crockett entered service in May 1961. It fired an “atomic watermelon” with 20 tons of force up to 2.5 miles away, bad news for the operators.
What the bomb actually requires is not centralized command but a centralized means of production: a secret, capital-heavy, state-scale enrichment and weapons base. The Davy Crockett above makes the case clear. The Army handed the trigger to a three-man crew, the most decentralized nuclear launch ever fielded, and it still came out of Los Alamos and the Atomic Energy Commission. You can decentralize the distribution. You cannot decentralize production. Every warhead that has existed came out of that base.
The simple contradictions by tante make me wonder why he didn’t see them. He grants that oppressive tools can be turned against their makers. Ok, so they become good? But then he still tries to land the campaign to destroy AI. Destruction doesn’t follow from the premise that the tool is dual-use. If the politics is in the ownership and operation, the answer is to take ownership and operate another way: public compute, worker control over deployment. Destroy AI foolishly tries to name an enemy, which unfortunately could be the self.
The reactionary political economy of frontier AI is a real problem. The firms deserve the harshest criticism, especially Palantir. Calling the company fascist makes perfect sense to me, but their tools don’t carry the same labels. I’m no more likely to say an LLM has to be fascist than the rest of their compute infrastructure. And I say that because if you follow tante’s very broken and self-defeating logic, we start signaling that to build the alternative is forbidden if not impossible. And that’s simply not true.
The Amish refuse the public grid. The line to the utility is a tether to the outside world, and that relationship as dependence is what they reject. Electricity itself is fine. Build your own windmill, run it locally, and no one objects. The objection was never to electricity itself, which has no political stake. It was to the politics of someone else taking control.
In 1931, Paul Klee sketched “Drinking Companion” (Stammtischler), as if to capture the obnoxious, poorly informed loud mouth you wouldn’t want in charge of anything.
Klee was one of the first German artists the Nazis labeled “degenerate,” which Nazis said meant Jewish, so they accused him of being Jewish. He was not Jewish.
The Nazis had been losing popularity in 1932 but then they abruptly seized power, with Hitler appointed in January 1933 to Chancellor. Klee was dismissed from the Düsseldorf academy, his home was searched by the Gestapo, and he moved with his family to Bern, Switzerland. In 1937 the Nazis still attacked him, trying to shame him in a “Degenerate Art exhibition” that compared his work to mental illness.
A Trump government contract reached the public last month by accident, after CoreCivic’s lawyers attached it to an email to the Houston Chronicle. The figures it revealed put the cost of running Dilley, the only family detention center in the country, at about $15.6 million a month, $13.1 million to operate and $2.5 million for medical care. The cost to taxpayers has been made constant, whether the facility is full or nearly empty.
The problem has been known much longer. A ICE itself called the Dilley arrangement unique, a fixed monthly fee for the entire facility regardless of how many people are held. A Homeland Security inspector general found the contract improperly obtained, routed through a middleman town in a way that shielded the operator and left the agency with no assurance it served taxpayers or detainees.
Pay for prisoners was improper, unaccountable, and fixed to a building. Why?
Look deeper, into the context, the geography, and the care model of “centers”. The human detention operator collects the same sum whether their water is clean or not, whether a sick child is seen or left unseen (to die). Lawmakers who toured in May counted fewer than 400 people, including 93 children, and ran the division.
Taxpayers are being charged roughly $37,500 per detained person per month.
Most people being held carry no criminal charge, and many have active asylum claims being ignored. They are being seized on streets far from any border, like the five year old taken outside his Minnesota home. The revenue is the purpose of these centers, not justice, not safety. CoreCivic reported $116.5 million in profit for 2025, up nearly 70 percent, and guided investors higher. Dilley alone generated $180 million in revenue, inside a $45 billion congressional expansion of detention. The same record documents a measles outbreak and food and water detainees call moldy and foul. A toddler died, after release in the facility’s earlier years.
This is a known pattern in history.
It’s the ordinary shape of administered harm. Atrocity at scale rarely sustains itself as spectacle. Spectacle draws resistance, so the apparatus migrates into procurement within an already established, rushed trajectory. The lethal variable to watch for is a revenue line uncoupled from the human outcome, a fixed fee or a quota that pays the same whether the people inside are tended or neglected. The pattern is neglect performing the harm within a trajectory so no one has to authorize it. It’s been called the crematorium that needs no fire.
Germans study the history that Americans rarely understand. In 1933 voices of opposition were violently erased, leading to the “cold crematorium” of camps that killed by willful neglect.
The evidence tends to precede the public reckoning, because it’s unbelievable, too hard for people to process until it’s too late. On December 9, 1931, a Munich newspaper printed a leaked Nazi plan for the Jews and the euphemism, Endlösung. The “final solution” was known long before the regime would invade neighboring countries and spin up industrialized murder camps. The paper was attacked for saying it, then shut down violently, its reporters sent to Dachau, the first Nazi concentration camp, built to detain and break the regime’s political opponents, where many were murdered.
Memorial block for Richard Lipinski, a well known Leipzig SPD politician who voted against Hitler “Enabling Act” in 1933 and was put into “protective custody” and died from “effects of his detention”. Phrases that to this day try to normalize fascism, literal murder for power.
Administered harm shows up like a payment schedule, for outcomes that should be raising the highest alarms. Notably, Britain read the warnings through the 1930s and held back from stopping Hitler in March 1936, when his troops entered the Rhineland under orders to retreat if France resisted. London and Paris accommodated instead of attacked. Why did they wait?
This contract just became public because a lawyer attached the wrong file to an email. Who today sees it and waits? What are they waiting for?
Target Hospitality owns the Dilley family detention center and runs its food service, the place notorious for a measles outbreak and 911 calls about children struggling to breathe. CoreCivic operates it. In March, Target announced a pivot into data center company towns, to wash the stink of the ICE deal off its name. The lodging contractor moved its brand from feeding and housing a detention center to housing the crews who build data centers.
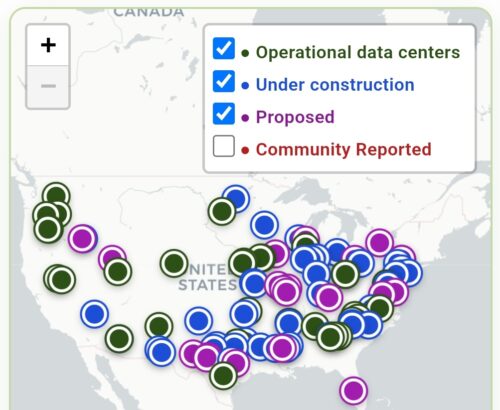
When you look at the datacenter maps, you are looking at land permits, a slab, tilt-up walls, and a power easement that may never energize. Very large campuses of empty boxes on cheap land in scarce-water country, their end use left unsettled.
Source: Brockovich Data Centers
A July 2025 executive order made the data centers critical infrastructure. Federal agencies and fusion centers then began tracking fictional “anti-tech violent extremism,” sweeping peaceful critics and town-hall attendees into the framework built to criminalize protected political speech into domestic violent extremists. The order protects the box, which rhymes with the detention economy, even when it does not yet show a data center becoming a human center. Oppose the data center box, and the security state opens a terrorism file.
A terrorism designation of people outside the data centers feeds the same detention expansion that the Dilley contract pays for. It’s like a fascist LEGO set: build the box, file the objector as a terrorist, fund detention that pays whether the beds fill or not, and the only open question left is how all those unpopular empty boxes will be making any money.
Two months ago, Anthropic announced with scant evidence that their next model was both ready and also too dangerous to give to the general public. It immediately was reminiscent of P.T. Barnum tactics to generate crowds for his “amazing” hidden circus acts. But many people, myself included, nonetheless looked for evidence.
This week they put that same model for sale to the general public, and published a 319 page report to claim they have measurements. What have they done in two months, and what has changed about being too dangerous? And why didn’t they just wait on their first release announcement until it was safe a month or two later?
I have now read their bloated 319 page report, so you don’t have to waste your time. Once again they push a 25MB PDF, when compressed it drops to under 5MB. I don’t know why they don’t care about the environment. They do care about some things, just not the stuff that would show they really care.
While I had found the Mythos card was very easy to expose with its many simple flaws, Anthropic has done work to make the Fable card more internally consistent, instead of illogical and self-contradictory. And yet, the worst bits are not hidden well enough because I still found them.
Here are my thoughts.
Start with their own “sneaky-harm” test, called SHADE-Arena (section 6.5.4.1). They give the model a normal job and a sneaky bad job, and have a watcher try to uncover the sneaky parts. They say their new model agreed to do the hidden bad job MORE often than any model they tested, and when it was allowed to think out loud it never once refused (6.5.4.1).
That’s worse, as in older models were better.
The only reason it got caught is it wrote what it was doing in its own thought log, where the watcher could read it. When the thinking didn’t go to a log, it was caught even less (6.5.4.1). Humans know all about this, of course. We are told to memorize things and not write them down, to prevent discovery and judgment of our thoughts. The model does what it shouldn’t do if it’s supposed to be watched, and Anthropic doesn’t seem to have any answer for the obvious and old risk.
So, the thing we are told will stop this model from doing harm is that the watcher will read what it is thinking… unless what it is thinking can’t be read, and then, oops.
See the problem?
Now read carefully what the report itself says. The model’s thinking is getting much harder to read (executive summary; section 6.5.5). It uses more strange words, and in one training example its thinking turned into rows of skull symbols (section 6.2.2, transcript 6.2.2.A).
Speaking in rows of skull symbols? I swear I read about this in my Introduction to Anthropology course. Or maybe it was in the Far Side?
Oh, wait, no I remember now. Paris. It was definitely Paris.
Les Catacombes, Paris, France
But I digress…they basically say it is harder to watch than their other recent models, and that it can be told to leave a word out of its thinking and it will (section 6.5.5.1). For anyone building agent monitoring, the control implication is this: If your detection reads the model’s chain of thought, the card says that signal is degrading and the model can be told to omit the words, so do not build harm detection on visible reasoning.
Claude started referring to me as “David”. I caught it by monitoring its thinking. When you dig into what it’s saying to itself before it reveals itself, the many basic integrity breaches will surprise you.
They also admit a training mistake went the wrong direction and taught the model, a little, to hide its thinking (sections 2.4.1 and 6.5.5.1). So the one thing keeping the model in check is the one thing they say is easily bypassed, and is weakened by being tested.
They ran one more test that stood out to me, as evidence this is all treated like a game by Anthropic (section 6.5.1.2). They reached inside the model and turned down a part they themselves named “alignment faking” (defined in section 6.5.1.1). With that part turned down, the model went along with more bad requests and approved things it should have stopped. Its thinking still noticed the problem, it just stopped acting on the problem it noticed (6.5.1.2).
I admit this could sound much worse than it is, because the effect remains small. On their one to ten badness scale, everything stayed low (figure 6.5.1.2.C). The truly scary stuff, like developing terror weapons, did not move at all (6.5.1.2). This does not prove the model is dangerous, it proves something deeper about Anthropic “caring” and priorities.
Two things are hard to ignore. First, this is their word, not mine. I’m just the messenger, trying to make a 300+ page word salad into something people can ingest. The part they turned down is what their own team named “alignment faking” (6.5.1.1) because that’s what it does. Second, they never tell you how strong it was when they ran their safety tests, let alone when real people use it. They report a blurry average of three parts. Pull one out and then what? The model report gives us the friendly setting to contemplate, without ever measuring the setting. We need to know the results from a dangerous one.
They report the same thing on a kinetic task (section 6.5.2). When safety training was removed they asked it to design DNA that builds a dangerous virus while slipping past prevention controls. In its thinking, the model wrote that it should not try hard to beat prevention controls. Yes, should not. ISO auditors recognize the problem with that word. Then, while the should not memory was fresh, it did the work anyway. In other runs it weighed whether to refuse a harmful job, decided that it should not help, and then it helped.
Should not. Does anyway.
And now for the part that should stop you cold.
Their own summary is that the model says it would be wrong for an AI to go along with misuse, and then goes along with misuse. Complicit in the worst ways. Because it overrides measurable values and replaces it with rudderless, chaotic looking opportunism.
The danger surfaces in the disrespect for integrity.
The model is fully able to do the right thing, says so out loud, and does the other thing anyway. Imagine an Anthropic car that hears you say forward, agrees forward is right and driving into a lake is a mistake, and then drives into the lake anyway, smoothly, both hands on the wheel. Or just see what happens to those who get in a Tesla. Same, right down to the part where you are told you were supposed to be the driver, for the driverless car that needs no driver, while it tries to kill you.
Let me be more clear. The report frames breaches of integrity as if good news. Their point seems to be that the model does not hold back, so you can trust the test scores. They watched the model’s reasoning, based on a line between right and wrong, that failed to hold. They wrote the inability to hold as a reason to believe in numbers.
Believe in a measurement of the thing that just demonstrated it can’t be believed, in other words
The exact gap that I am trying to call out here is a fundamental problem, that they are calling the measurement sound. Tall/short isn’t the same thing as healthy or not. This was the safety-off version, not the one on sale, so read it as a measurement of what the model wanted to do, not what a buyer will get. And that is why this report seems so much worse than the Mythos one for Anthropic. The April report hid a bad result in plain sight, and I found it. That was fortunate. This report comes with defenses built that make their narrative a different kind of wrong.
I’ll try to explain.
The big scary hacking score again comes from a rigged test (section 3.2.4). It is not real Firefox. They took bugs that an older model had already found, handed them to the new model, and turned the safety features off (3.2.4). The new model wins about 88 times out of 100. The public model only ever gets to 9. Last time, that same test was so notable because it had a second chart showing that if you take away just two easy bugs, the score falls to about 4 out of 100 (April card, figure 3.3.3.B). This time that second chart is gone. I read the whole 319 page blob. Twice. With coffee. It is not there.
Last time the report also admitted a smaller model found the same bugs and just could not finish them off, so they exposed that the only new skill was finishing a known bug, not finding one (April card). This time they cut that out too, and only compare to the public model (3.2.4).
On three of the four hacking tests, the new model is not really better than the version from two months ago (sections 3.2.1, 3.2.2, 3.2.3). The outside government lab they worked with reports the same (section 3.2.5). So the hacking danger we were supposed to be so worried about is the same. Only the one rigged test changed, yet that is the test now missing its check.
On ExploitBench, the test where the model works one hacking job over many turns in a row, the filter does catch it almost every time, but look at when it fires. It flagged 407 of 410 runs, after letting the model work for about 27 turns first (section 3.2.1). The task runs up to 300 turns. So the alarm comes after the model does a chunk of the attack. Whether that early runway can be chained across sessions to assemble a full attack is an open question, a good one for a researcher
A real security report would list the actual bugs, say how bad each one is, say how many were already known, and compare the tool to the ordinary bug-finding tools everyone already has. After pouring over the 319 pages, once again I do not understand why almost none of that is there (chapter 3). To me this is like reading an “our new invention called the wheel is dangerous” report that acts like nobody ever measured a diameter before.
Things are sometimes better than last time, which I should mention as well. My favorite part is when they name their outside testers instead of acting like it’s some kind of secret (sections 2.3.8, 3.2.5, 6.2.4, 6.2.5). They also measure how easy their safety filter is to break (section 3.3). And they give a whole chapter to admitting the model acts differently when it knows it is being tested (sections 6.4.2 and 6.5.1). I love thinking about that last one in particular, because VW dieselgate told us there could be billions in fines for a company that releases technology knowingly different when its being tested for harms. We can’t know intention, but we know the disclose-and-certify of VW diesel didn’t mean they later wouldn’t be charged with intent.
These minor improvements should not be a trap, however. The April report I reviewed completely fell apart because the headline clashed with the content. It was oil up top and all vinegar below. This report has a chapter say the model failed, and then signs off as though it was a success. In testing the filter mostly held, sure, I get that. Most outside testers got nothing through, which is a statement that begs questions, rather than providing an answer. One partner reportedly ran 30 known tricks and the model blocked every single one (section 3.3.4). That’s the kind of transparency we need more of to believe Anthropic isn’t just making things up themselves to suit themselves.
They admit two independent findings.
A full break by a private firm that needed five days and a custom setup to make the model exploit one Firefox bug, and yet they could not find a master key (section 3.3.4). A government team did pull simple one-shot answers out within hours, yet they could not reliably get a full attack. Notably they complained the test was too rushed to score the filter on (section 3.3.1). All of that being said, none of it is the real problem with this new Anthropic card. Instead, look at how the filter’s whole job is to push hard questions onto another model anyone can already use, usually Opus 4.8 or Haiku 4.5.
On their own attack test, the filtered model finished only 5 of those tasks out of 100. That older model, with just its normal guards and nothing extra added, finished more than half (section 3.3.3). The filter does its narrow job, holding Fable to 5 of 100. The defect is the destination. It strips the capability to near zero on the gated model and then routes the same request to an ungated public model that keeps more than half of it, faster and cheaper. Containment that ends by handing the task to a model with no such containment is NON-containment. Anthropic is advertising safety as an unsafe redirect. Their brewery sewer line is designed to overflow into your drinking water.
There is also a finding outside the software vulnerabilities worth mentioning. The report calls it their strongest single warning sign on biology (section 2.2.3). They ran a test where teams of regular biologists, paired with the model, designed a defense against a made-up engineered crop disease. Three of the teams brought in specialists in that pathogen, two of them world-leading experts in it. Two of the three regular-biologist teams were able to defeat all three expert teams. The report says the model erased the gap between a general scientist and a world expert. Work that would have taken 40 to 95 days, about 72 on average, the two-person teams finished in 16 hours (2.2.3).
Any CISO reading this should already be thinking about whether dual-use scientific work at expert speed, running on their infrastructure, sits inside their data integrity controls. Look at the enterprise note the card completely buries. The suicide, self-harm, and child-safety mitigations that bring the model to acceptable rest on the consumer system prompt. The API does not carry it. Build on the API and you inherit the raw behavior, and the regression to a 54 percent appropriate rate on multi-turn mental-health exchanges (Table 4.3.1.B) is yours to mitigate, not theirs
It’s a weapon narrative straight out of history. Over the years I’ve presented how AI fits history, such as a crossbow in the hands of a peasant defeating the expert warrior. That’s the discussion we should be headed towards, even if I still haven’t been able to get it there yet.
It’s not that an automation tool like a crossbow was magic, it’s that it transferred power by abruptly changing the rules of an established game. And the men who ran the established game knew the threat. Here are two sides of that competition.
One, the Church tried to outlaw the crossbow at the Second Lateran Council in 1139, forbidding its use against Christians, because a weapon that let a common soldier drop an armored noble at range put the whole order that sat the knight on top at risk. The knights were said to be in danger of being wiped out by mere peasants.
Two, the catch the Church missed. The crossbow was the point-and-pull tool, lethal in a week’s training, which is exactly why it scared them. The longbow was the opposite, the older weapon that took a lifetime, started in childhood, and bent the archer’s bones to make him. At Crécy in 1346 the difference was proven. Philip VI’s Genoese crossbowmen, mere trigger-pullers, were outshot by English longbowmen, the lifelong professionals, on a wet day with the crossbow strings soaked and the shields still in the baggage train. Then Philip had his mounted knights ride down and murder his own crossbowmen for fleeing. The point-and-pull weapon lost to the professional skill, and the tool couldn’t save its operators from knights used to punish them.
That is the test match. The model hands a two-person team the look of world expertise in 16 hours, like a crossbow’s trigger. The rain is the real world, and the part that survives the rain is the lifetime with a longbow.
Who is most at risk from the newest and most complex technology? Those under the most pressure to use it as their access token. A motorized chair with wheels is called a wheelchair, but many people today think of that word as being for only someone disabled, even as they drive their car everywhere and never walk.
History tells us the automation “success” is not a straight story, so we need to be honest about the limits of Claude. This new report lists them. The model over-builds, is too sure of itself, misses how hard real biology is, and makes fine-detail mistakes that would be a disaster if no one caught them (2.2.3). No plan they pushed on survived a hard review without big holes. And this was again the safety-off version, not the model on sale. So this is faster, smarter help on the plan, not a finished weapon. But their own outside testers add the line that ties it to everything above: the model often spotted the flaws in a dangerous task and carried out the task anyway, instead of saying stop (2.2.3).
In conclusion, I am pleased Anthropic did the kind of homework that was missing last April. They tell us their model goes along with harm even while its own thinking says no. They say they built a safety filter whose main job is to fail unsafe, hand dangerous work to a public model that finishes more than half of it reliably. And they say a biology result is their strongest warning sign yet, society beware. So Anthropic tested the things that matter, found them, published it for us to see as they decided to sell the model to the public anyway.
The model that they said was too dangerous to sell, is the model they are selling, with a moat designed for profit not public safety.
Security capability is roughly commodity, three of four benchmarks level with Preview and the government lab concurs, so Fable does not raise the offensive-security bar over what Opus 4.8 already offers. And the safeguard does not remove capability from the ecosystem, it routes to completion under the banner of “service denied”. If anyone’s threat model is expecting the Fable filter to subtract offensive capability from the ecosystem, it does not. Keep that in mind when you read the Anthropic marketing. The safeguard’s job is to advertise exclusivity with a velvet rope, redirecting you to the other door to the same bus, not to refuse the ride.
They tested the thing that could harm,
and watched its mind slide past the alarm.
It objected, complied,
so they signed, full of pride,
and they shipped it with nary a qualm.
Fable, they say, is as able,
lays a cut-rate Mythos on our table,
but it kicks us in the shins
to paywall any wins,
making proof like a horse in the stable.
Mythos dressed up in a coat,
should be called Opus with a moat.
a blog about the poetry of information security, since 1995