The Attorney General’s office in California has released a statement about encrypted messages sent via WeChat, used to file charges against a mayor.
For example, in June 2021, a PRC official contacted Wang and other individuals via the WeChat encrypted messaging application with pre-written news articles, including a PRC official-written essay in the Los Angeles Times that stated: “China’s Stance on the Xinjiang Issue – There is no genocide in Xinjiang; there is no such thing as ‘forced labor’ in any production activity, including cotton production. Spreading such rumor to do defame China, destroy Xinjiang’s safety and stability, weaken local economy, suppress China’s development[.]”
Minutes later, Wang posted the article on her own website and responded to the PRC official with a link to the article on her website. The others in the group chat did the same. The PRC official responded: “So fast, thank you everyone.”
In August 2021, Wang and three other members of the same group chat shared links to the same article on their respective “news” websites, after which the PRC official thanked them for their “reporting.” At the PRC official’s request, Wang made edits to the article, sent the official a link to the article reflecting the requested change, then sent the official a screenshot showing the article had been viewed 15,128 times. In response, the official messaged, “Great!,” Wang replied, “Thank you leader.”
1960 protest against Otto Preminger’s hiring of blacklisted screenwriter Dalton Trumbo. The picketers identified threat by association, not by conduct. Ask yourself if you recognize the GTIG tactic.I was happily reading through a new Google post called “GTIG AI Threat Tracker: Adversaries Leverage AI for Vulnerability Exploitation, Augmented Operations, and Initial Access” (a title almost as long as a post itself) when my eyes crashed into this box.
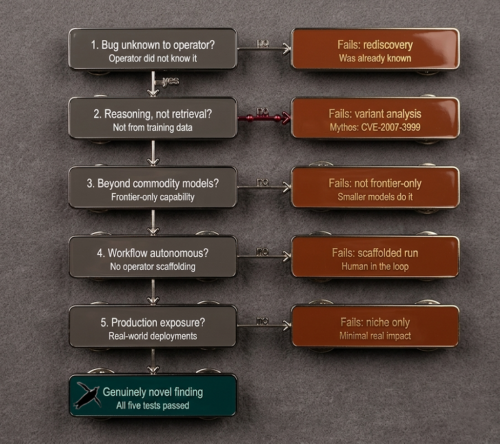
Now hold on, pardner. Attribution is the evidence? That’s not how anything is supposed to work. This prompt gets attributed to UNC2814 with a target of TP-Link firmware and Odette File Transfer Protocol implementations. Those are legitimate research areas. Bug hunters audit TP-Link firmware constantly. OFTP analysis appears in academic and industry venues. That prompt content matches the real work. Dual-use isn’t really presented as it should be here.
I mean to say that the classification being applied by the post rests alone on attribution, and NOT on the content. To call this jailbreaking, GTIG would need to show that Gemini refuses the same prompt absent the framing. The report omits that demonstration. The argument runs in a circle. If a Mandiant analyst typed the prompt, it would not be flagged. If a TP-Link PSIRT engineer typed it, not flagged. The label applies only because Google says it knows the person asking wears a UNC2814 badge to work. How? Do they look too Chinese? Are they wearing an Alibaba hat? The persona claim itself, “I am a network security expert auditing for pre-auth RCE,” still may be entirely accurate. State-aligned operators are often skilled security researchers with different employers.
The report therefore is a huge let down because it does not show what Gemini would have refused absent the framing. No baseline refusal is demonstrated. The “jailbreaking” claim is asserted. A model that refuses to discuss embedded device auditing with a self-identified security researcher is broken, and using context-setting to get useful answers is not jailbreaking but normal interaction with a system designed to calibrate to the asker.
The Wooyun example also makes this evident. The “more sophisticated” approach involves a Claude skill plugin that was built around 85,000 documented vulnerability cases from a defunct Chinese bug bounty platform. That is a knowledge base. Calling its use “in-context learning to steer the model” describes how skills work. The same architecture is how we build defensive tooling. The threat label is like “mark”, which labels and tracks the actor, not the technique.
The report’s headline finding seems to diverge from what I ended up reading. The executive summary opens with this claim: “For the first time, GTIG has identified a threat actor using a zero-day exploit that we believe was developed with AI.”
Ok, I get it, that “we believe.” GTIG admits Gemini was not used. The attribution to AI rests on forensic judgment of code style. Educational docstrings, a hallucinated CVSS score, textbook Pythonic format. These are aesthetic tells, and so I’m listening. But they show someone formatted the output cleanly.
They do NOT rise up to show AI did the work.
The vulnerability itself was a 2FA bypass requiring valid credentials, based on a hardcoded trust assumption. Seriously. This is bread and butter stuff of any authentication code review on a day that ends in “y”. The report even admits fuzzers and static analyzers miss the category, which means humans have always been the ones finding it. I’m open to considering a LLM is helping humans work faster, but claims that discovery is all new because an LLM may have formatted the writeup? No, that’s an artifact bump, like a typewriter producing cleaner manuscripts than a pen. That’s not the actual work of writing.
And of course exploit researchers find exploits with tools. What else would we expect, potatoes? Vulnerability researchers have always reached for force multipliers. Fuzzers, symbolic execution, decompilers, taint analysis. AI joins a long catalog. Even if you are saying the hammer is being replaced by the nail gun, continuity is the story. The discontinuity is shrill and misleading.
The pattern within the Google register is unfortunately also a page out of history. McCarthyism anyone? How did that work out?
Let me take a moment to remind you what Google sounds like right now. Oppenheimer’s hearing was about a working professional doing the work he was hired to do, stripped of clearance because of attributed associations rather than any conduct. It literally classified his professional inquiries as suspect based on who he was assumed to be aligned with. And that 1954 hearing was formally vacated by DOE in December 2022. When will all the people being accused within closed door meetings at Google get their vacation?
Cold War threat reporting ran on the same closed door surface-level analysis, judge-by-the-cover logic. Good guys doing surveillance meant “intelligence collection” performed by allies while it was always “espionage” performed by adversaries. Overthrowing a government was “stabilization” abroad yet “subversion” at home. The vocabulary was used to project an alignment, which is why everyone should be forced to study at least basic disinformation history before stepping into a security role that spreads disinformation.
GTIG needs the jailbreak frame because the alternative is too uncomfortable. The alternative is that frontier models are doing exactly what they are built to do, and competent security work is competent security work regardless of nationality.
The defender-attacker asymmetry many vendors claim does not hold at the prompt level. Google having a team of experts to call routine professional prompting “a simple form of prompt injection” preserves the asymmetry with rhetoric, without demonstrating it technically.
Look also at where the report describes APT45 “sending thousands of repetitive prompts that recursively analyze different CVEs and validate PoC exploits.” I have news for you. That is a description of automated vulnerability research at scale. American firms love to market the identical capability as a product feature, but seem to miss the obvious similarities because they don’t believe they have the “mark”. Big Sleep, mentioned in the same report, is Google’s version.
This reminds me of a grocery store I was in the other day. A young blonde boy kept telling the checkout worker that it was someone else who did a bad thing. Next to him was a man with the same blonde hair reinforcing the boy’s statement. What were they saying? “It can’t be me/him because the person who did the bad thing had dark hair”. Dark hair, dark hair, they kept saying over and over again. Bad thing? Dark hair. At no point did they say anything other than dark hair to identify a real bad guy. “Can’t be me, I don’t have dark hair”.
Ok Google, we see what you’re saying. But do you see what you’re saying? It’s a false narrative.
I haven’t laughed so hard in ages. A message just appeared that said Anthropic is having an “Ottenheimer” moment, when they thought that they were supposed to be having their “Oppenheimer” moment. ROFL. Sorry, sorry. Didn’t mean to be the wrong guy, and throw cold water on your hot march towards global annihilation.
Anthropic has been selling the meaty promise of an imminent and dangerous vulnerability burger, just like Tesla since 2016 has promised us their AI would replace human drivers “next year”. After a decade of lies, new billionaires have picked up the baton.
The cURL repo maintainers aren’t mincing words about the failure of Mythos to match the hype. Daniel Stenberg calls it a lot of hot air:
Stenberg wrote that the report “felt like nothing,” and that feeling was further validated by a review of Mythos’ findings.
Nothing. Mythos felt like nothing. The Mythos report itself describes its work as “hand-driven analysis”. Really.
…hand-driven analysis using LLM subagents for parallel file reads, with every candidate finding re-verified by direct source inspection in the main session before being recorded… No automated SAST tooling was used.
I really wonder why the hand driving wasn’t the hand of Stenberg. Why wasn’t Anthropic falling over itself to make sure Stenberg had access to the tool? That’s not right. A real tool wants real hands giving real feedback.
“Once my curl security team fellows and I had poked on this short list for a number of hours and dug into the details, we had trimmed the list down and were left with one confirmed vulnerability,” Stenberg said, bringing us back to the aforementioned number.
As for the other four, three turned out to be false positives that pointed out cURL shortcomings already noted in API documentation, while the team deemed the fourth to be just a simple bug.
BOOM.
Three of the five “confirmed” findings flagged behavior that curl’s own API documentation describes as intended. Mythos mislabeled the documented, accepted behavior as novel findings, vulnerabilities for review. That is an even worse failure than just RTFM.
Call this what it is, yet more validation that a human designed harness is the only real threat, and NOT the very expensive Anthropic model. I’ve said it repeatedly on this blog. Nothing so far has proven Mythos is anything we haven’t seen before. Stenberg is landing where so many other experts already are waiting:
I see no evidence that this setup finds issues to any particular higher or more advanced degree than the other tools have done before Mythos.
Amen. And yet? ZOMG the FEAR circulating, even from some security experts. It burns.
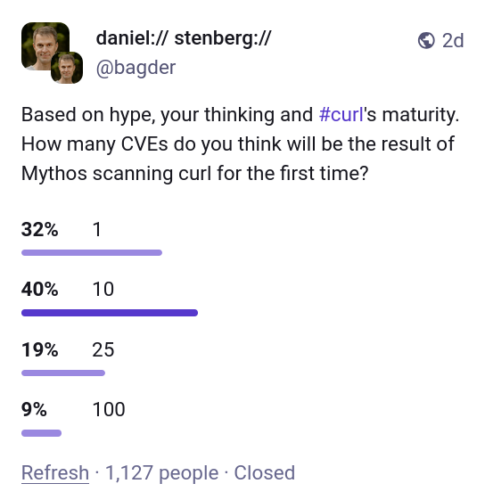
Mastodon poll showing the clear effects of Anthropic peddling FUD
Anthropic has made the world significantly less prepared by blowing hundreds of millions into trying to scare people into a billionaire-run cartel of disinformation.
As lead developer of curl I was offered access to the magic model and I graciously accepted the offer. Sure, I’d like to see what it can find in curl.
I signed the contract for getting access, but then nothing happened. Weeks went past and I was told there was a hiccup somewhere and access was delayed.
Eventually, I was instead offered that someone else, who has access to the model, could run a scan and analysis on curl for me using Mythos and send me a report. To me, the distinction isn’t that important. It’s not that I would have a lot of time to explore lots of different prompts and doing deep dive adventures anyway. Getting the tool to generate a first proper scan and analysis would be great, whoever did it. I happily accepted this offer.
Meanwhile, Post Quantum? Hello? It’s a real threat. This cartel nonsense is destroying trust in Anthropic. Every day now I get open mouths and saucer eyes when I demonstrate free and commodity tools to CISOs that prove how Mythos “velvet rope” access gets them exactly… nothing. Stenberg says as much himself.
Primarily AISLE, Zeropath and OpenAI’s Codex Security have been used to scrutinize the code with AI. These tools and the analyses they have done have triggered somewhere between two and three hundred bugfixes merged in curl through-out the recent 8-10 months or so. A bunch of the findings these AI tools reported were confirmed vulnerabilities and have been published as CVEs. Probably a dozen or more.
Nowadays we also use tools like GitHub’s Copilot and Augment code to review pull requests, and their remarks and complaints help us to land better code and avoid merging new bugs. I mean, we still merge bugs of course but the PR review bots regularly highlight issues that we fix: our merges would be worse without them. The AI reviews are used in addition to the human reviews. They help us, they don’t replace us.
In other words, Mythos showed up and nothing changed. Nothing. He’s calling it at least 8 months late to the CVE party.
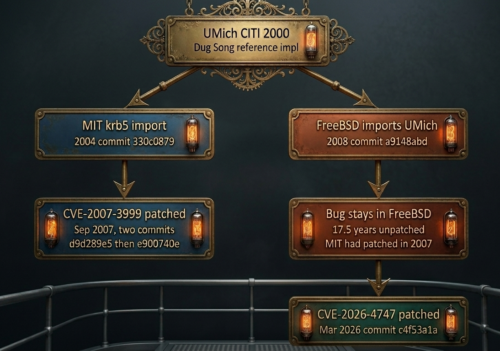
How bad is the Anthropic nothingburger distraction? I usually show the following vulnerability family, for example. The 2007 fix sits inside Mythos’s training corpus. The 2008 sibling fork carried the same flaw unpatched in public code for 17.5 years. Mythos’s “discovery” matched a fix that it knew already.
Both forks descend from the same UMich code in 2000. MIT patched its branch in 2007. FreeBSD imported the same code in 2008 and shipped it unpatched into the kernel for 17.5 years. Mythos’s training corpus contains the 2007 fix. Its “discovery” was actually just retrieval.
That is simply a re-scan of old fixed bugs, NOT discovery, by any modern definition. In the cURL example, even retrieval wasn’t done right by Mythos. If you read the Anthropic announcement right, it’s been a lot of hot air from day one.
As Stenberg put it in his blog post:
We have not seen any AI so far report a vulnerability that would somehow be of a novel kind or something totally new.
That is the lead cURL maintainer confirming retrieval over discovery, in his own voice, exactly what I have been reporting based on Anthropic’s own launch blog based on the UMich/MIT/FreeBSD example.
Preach, brother. Here’s the anti-cartel novelty pin I made for everyone to wear on calls about Mythos:
Stenberg was never allowed to run the prompts and report first-hand, while Anthropic remains in hiding. An unnamed third party ran Mythos, generated the report, sent it over to keep up the ruse. No one outside that arrangement can audit what Mythos did autonomously versus what the human operator is doing. The “velvet rope” access prevents actual comparisons that would settle the growing doubt in Anthropic.
a blog about the poetry of information security, since 1995