YouTube has been surfacing a LOT of synthetic war content lately, and the attribution question deserves more care than the platform gives it. The @BenHodgesUpdates channel is not Hodges, not affiliated with him, and the production cadence is impossible for genuine interviews. Whether it runs for ad revenue or for Moscow, or both, matters less than you’d think, because hyper-inflated Ukrainian victory content serves Putin’s KGB-trained interests either way: saturate the audience with imminent Russian collapse, and every week reality fails to deliver erodes trust in the real analysts whose names were stolen to sell it. President Wilson’s propagandists understood this in WWI, and so do the YouTube content slop factories perhaps sitting in Texas and Florida.
This unauthorized impersonation channel is reportable under YouTube’s impersonation and misleading-content policies. And you should report it. But more importantly you should ask why YouTube engineering doesn’t flag such dangerous integrity breaches of their platform.
Start with the channel description, which ends with “For business inquiries and partnerships: [Your Email Address Here]”. A template that for years never filled in this obvious blank, is a giant flag all on its own.
Then look at the timing and monetization model. The channel joined November 20, 2022, yet all 14 videos were rushed in the last four weeks at roughly one per day. That’s an aged or purchased account repurposed for a content farm. And every video is a 23–29 minute “exclusive” with the same general. Past the eight minute mark YouTube permits mid-roll advertising, meaning a daily half-hour of synthetic narration is for revenue generation on fraud, not interview scheduling. Compare it with the real Ben Hodges who does real interviews (Ukrainer, CNBC, BBC, Silicon Curtain). No General, including him, runs a daily half-hour sit-down interview pace like this.
And what about the data? I see 15.8K subscribers and 340K views off 14 videos in three weeks, consistent with the documented wave of AI-narrated Ukraine war slop channels that clone the voices of Hodges, Petraeus, and similar figures over stock footage.
Content fails as well. Titles are “Ukraine Just ERASED Putin’s Crown Jewel… BLINDS Putin’s Nuclear Fleet FOREVER | Gen Ben hodges”, with inconsistent capitalization across uploads (“Ben Hodges”, “ben hodges”, “Gen Ben hodges”), a dropped-letter typo (“ULEASHED Hell”) of the kind language models almost never make, betraying the human hand retyping machine output into the upload form, as well as ellipses, all-caps panic verbs. It’s lighting up as hallmarks of machine-generated titles, only lightly supervised.
Source: YouTube
We haven’t even clicked into a video yet and already it’s a clear takedown case, built on an account that sat aged for years before activation three weeks ago.
The pipeline of metadata convicts the channel on its own. Hello YouTube? Hello?
Now, the juicy part. What about content spread by the channel? Before I begin, let me refer to my two degrees with a specialization on asymmetric conflict and disinformation. That’s not an appeal to any sense of authority, rather to say what follows isn’t a light skill picked up in a day. I highly recommend study and practice of this subject, as you will see improvements in your own ability to detect subtle threats. That being said, YouTube could easily detect this with some simple engineering by experts and expert tools.
The seed: a bridge near Chonhar connecting occupied Crimea with Russian-controlled southern Ukraine was damaged in a Ukrainian drone strike overnight on June 7, confirmed by the Ukrainian military, and a second drone strike on June 9 halted traffic again, followed by a reported missile strike on the Henichesk–Arabat Spit bridge early on June 10. Note the sourcing gradient: June 7 is confirmed by Kyiv with video, June 10 rests on the Russian occupation official Saldo, and the June 11 reports of bridges hit at Armiansk and Krasnoperekopsk trace back to social media posts relayed by news aggregators. The script bases its loudest point of certainty on the least confirmed ones.
The laundry: the commander of the 1st Separate Assault Regiment said the Chonhar strike was carried out specifically to cut fuel supplies to the Russia’s 37th Motorised Rifle Brigade.
The gap: the drone strikes punched roughly one-metre holes in the bridge deck while the structural ribs were not compromised, and there is no confirmed evidence the bridge has been destroyed; the immediate military effect remains difficult to assess independently. Russian engineers were already running a pontoon crossing at Chonhar, visible in satellite photos. The script converts that into “permanent damage,” six bridges “rendered operationally useless,” and 110,000 troops in a “logistical trap.” Note the title says 80,000. The script says 110,000. The pipeline doesn’t reconcile its own numbers.
The fog: Pantsir blind spots “mapped and cataloged,” electronic warfare signatures “recorded and analyzed,” a four-hour attack wave from midnight to 0400, “weeks of patient, methodical intelligence collection.” No public source contains any of this. It’s the texture of analysis without sources, which means an LLM hallucinating a dense fog to disappear the real headlines.
The artifacts: the interview has no interview. No questions, no first-person voice of a retired three-star. It’s omniscient-narrator machine-generated prose that has “Gen. Ben Hodges” stapled to it, so thinly connected it may as well be Donald Duck.
Now let’s go deeper into the ruse, as a logic test of integrity. An analytic framing blows the script apart.
Bad addition: Title: 80,000. Opening: 110,000, as 50,000 mainland plus 60,000 Crimea. Which?
Bad geometry: The “encirclement” claim depends on Kerch Bridge being the only supply route other than Black Sea ferries to 50,000 mainland troops. But cutting Crimea crossings isolates Crimea, not the other way around (the mainland). Forces in Zaporizhzhia and Kherson are supplied through their eastern land corridor from Rostov through Mariupol, Berdiansk, and Melitopol. It’s common sense, really. And the script admits as much because the land bridge is slipped out as a shift of supplies to “Russian port logistics along the Sea of Azov coastline”. The real General Hodges would be talking about the land corridor as the target, meaning hype about a Crimea artery doesn’t square his circle.
Bad timeline: The opening states “between June 9th and June 11th… six bridges in 48 hours,” then states Chonhar was first struck with significant damage “in the days preceding June 9th”. The 48-hour window is a hallucination contradicted minutes later. Also, since I was quite open on this blog about naval drone strikes in 2023 (as well as Elon Musk being Putin’s muppet, and the October 2022 unmanned surface vessel raid on Sevastopol that opened the genre after a Neptune missile sank the Moskva) let me point out another tell. This script says strikes were “in 2023 and 2024”. Nope. The drone strike was July 2023, full stop. The next successful attack came in June 2025 and it was no drone: SBU agents spent months mining the underwater supports and detonated 1,100 kg of TNT equivalent at 4:44 in the morning. Nothing landed in 2024, and that gap year is well-known for well-known reasons.
Bad physics: The claim “pontoon bridges cannot carry main battle tanks at scale” is dumber than rocks. Russian PMP ribbon bridging is for… tanks. The actual problem is being vulnerable to attacks, not basic operations.
Bad strategy: When the script says “none of this happens overnight” it clashes with its earlier claim that Ukraine reports “direct operational consequence” of day old strikes is “observable reductions in incoming artillery fire”. Which is it?
Bad source: We have no confirmed evidence the bridge has been destroyed. The effect is still hard to assess, while we do know the deck has one-meter wide holes in it. Meanwhile the script floats all kinds of intelligence detail with zero evidence, about Pantsir maps of blind spots and EW signatures, attack waves, contingency doctrines, share of traffic and re-rerouting… none of it sourced.
The method of military intelligence spreading disinformation, since at least President Woodrow Wilson’s efforts in WWI, has been to take a checkable fact and surround it with unfalsifiable details.
After WWI Edward Bernays left Wilson’s Committee on Public Information to sell the same methods to corporations. By his own account, a foreign correspondent told him in 1933 that Goebbels kept Crystallizing Public Opinion in his library and was using it as a basis for the campaign against the Jews of Germany.
The effect of this YouTube channel is a hallucinated geography taped together from a few precise details.
A real analysis channel with a real General would be the exact inversion, where the details are not exact yet the geography is always right.
Let’s set aside the fact that what Elon Musk says about cars is a provable lie.
Focus on his math here.
Source: Twitter
over 500% *less*
That’s Elon Musk math. On fire safety.
Now look at Trump, November 2025, announcing the GLP-1 deal with “tremendous cuts, 200 percent, 300 percent, 500 percent, 700 percent and even more than that”. Then in his prime-time address he claimed negotiated reductions of 400 to 600%, with the July version running to drug price cuts of as much as 1,500 percent, numbers he himself called beyond what anyone thought achievable.
These grifters, obviously operating as cruel con-men, converged in the public eye and then… kept on grifting.
A percentage decrease past 100 means the drug seller pays you to take it, or that the Tesla extinguishes nearby fires.
Idiots?
No. Historians study how Hitler used a strategy of being considered an idiot, a clown, to disarm his targets and kill them.
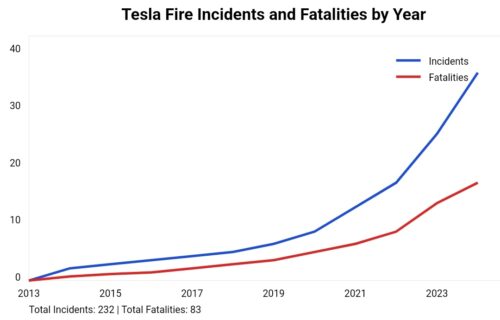
“Parked Teslas Keep Catching on Fire Randomly, And There’s No Recall In Sight” –The Drive 2019Source: tesla-fire.com
The problem in the West isn’t just one man, one speech, one product. The problem is how markets run unregulated, without sufficient safety against those spreading hate through “free speech extremist” tactics of targeted fraud.
Now let’s talk reality.
The US fleet baseline is vehicles with a median age over twelve years, plus arson, plus parked junkers, plus carbureted antiques. Out of that ancient and often unmaintained fleet, electric fires are a leading or second cause of fires. Electric fires, as in combustion engines have batteries and wires that start fires. Take the combustion away and you still have the exact same cause of the fire. Electric fires.
The NFPA cause data for highway vehicle fires puts electrical distribution and mechanical failure at the top of ignition sources. The gasoline is the accelerant, rarely the ignition. Fuel tanks don’t spontaneously combust; frayed wiring harnesses, failed alternators, and leaking fluids onto hot exhaust do the igniting. So Musk spread dangerous lies, as his “massive amounts of highly flammable fuel” framing inverts the mechanism. An EV carries both the energy store and the electrical system, and when the energy store itself enters thermal runaway you get a fire that reignites for days and resists suppression.
Tesla is the massive amounts of highly flammable fuel (volatile chemical cells), with a known unsafe and unnecessary design flaw. Read the “nail in Tesla coffin” report, and you will see how and why other electric car makers don’t burn. Fire is a big Tesla problem.
Teslas, at the time Musk blew the most smoke about fire, were almost all under five years old, garaged, owned by affluent early adopters who didn’t know enough about him or cars in general to see the fraud. New gasoline cars, excluding electrical causes of fire, against Teslas was the honest comparison. More to the point, Tesla engineering grows worse over time, so their design flaws not only don’t get investigated, they compound and increase in likelihood and severity.
The CEO of Tesla does in fact seem to exhibit Ford-like “permanent improvisation” (abuse of trust) that signals fascism, and he repeatedly makes only positive Hitler references.
And three years before that, he kept saying his vision of “better” is the world on fire:
“Parked Teslas Keep Catching on Fire Randomly, And There’s No Recall In Sight” –The Drive 2019
The warnings about Elon Musk since at least 2019 have come to this. The UK now has a lot of explaining to do for enabling militant hate campaigns by the maker of explosive concentrated chemical fuel storage (Tesla).
Two months ago, Anthropic announced with scant evidence that their next model was both ready and also too dangerous to give to the general public. It immediately was reminiscent of P.T. Barnum tactics to generate crowds for his “amazing” hidden circus acts. But many people, myself included, nonetheless looked for evidence.
This week they put that same model for sale to the general public, and published a 319 page report to claim they have measurements. What have they done in two months, and what has changed about being too dangerous? And why didn’t they just wait on their first release announcement until it was safe a month or two later?
I have now read their bloated 319 page report, so you don’t have to waste your time. Once again they push a 25MB PDF, when compressed it drops to under 5MB. I don’t know why they don’t care about the environment. They do care about some things, just not the stuff that would show they really care.
While I had found the Mythos card was very easy to expose with its many simple flaws, Anthropic has done work to make the Fable card more internally consistent, instead of illogical and self-contradictory. And yet, the worst bits are not hidden well enough because I still found them.
Here are my thoughts.
Start with their own “sneaky-harm” test, called SHADE-Arena (section 6.5.4.1). They give the model a normal job and a sneaky bad job, and have a watcher try to uncover the sneaky parts. They say their new model agreed to do the hidden bad job MORE often than any model they tested, and when it was allowed to think out loud it never once refused (6.5.4.1).
That’s worse, as in older models were better.
The only reason it got caught is it wrote what it was doing in its own thought log, where the watcher could read it. When the thinking didn’t go to a log, it was caught even less (6.5.4.1). Humans know all about this, of course. We are told to memorize things and not write them down, to prevent discovery and judgment of our thoughts. The model does what it shouldn’t do if it’s supposed to be watched, and Anthropic doesn’t seem to have any answer for the obvious and old risk.
So, the thing we are told will stop this model from doing harm is that the watcher will read what it is thinking… unless what it is thinking can’t be read, and then, oops.
See the problem?
Now read carefully what the report itself says. The model’s thinking is getting much harder to read (executive summary; section 6.5.5). It uses more strange words, and in one training example its thinking turned into rows of skull symbols (section 6.2.2, transcript 6.2.2.A).
Speaking in rows of skull symbols? I swear I read about this in my Introduction to Anthropology course. Or maybe it was in the Far Side?
Oh, wait, no I remember now. Paris. It was definitely Paris.
Les Catacombes, Paris, France
But I digress…they basically say it is harder to watch than their other recent models, and that it can be told to leave a word out of its thinking and it will (section 6.5.5.1). For anyone building agent monitoring, the control implication is this: If your detection reads the model’s chain of thought, the card says that signal is degrading and the model can be told to omit the words, so do not build harm detection on visible reasoning.
Claude started referring to me as “David”. I caught it by monitoring its thinking. When you dig into what it’s saying to itself before it reveals itself, the many basic integrity breaches will surprise you.
They also admit a training mistake went the wrong direction and taught the model, a little, to hide its thinking (sections 2.4.1 and 6.5.5.1). So the one thing keeping the model in check is the one thing they say is easily bypassed, and is weakened by being tested.
They ran one more test that stood out to me, as evidence this is all treated like a game by Anthropic (section 6.5.1.2). They reached inside the model and turned down a part they themselves named “alignment faking” (defined in section 6.5.1.1). With that part turned down, the model went along with more bad requests and approved things it should have stopped. Its thinking still noticed the problem, it just stopped acting on the problem it noticed (6.5.1.2).
I admit this could sound much worse than it is, because the effect remains small. On their one to ten badness scale, everything stayed low (figure 6.5.1.2.C). The truly scary stuff, like developing terror weapons, did not move at all (6.5.1.2). This does not prove the model is dangerous, it proves something deeper about Anthropic “caring” and priorities.
Two things are hard to ignore. First, this is their word, not mine. I’m just the messenger, trying to make a 300+ page word salad into something people can ingest. The part they turned down is what their own team named “alignment faking” (6.5.1.1) because that’s what it does. Second, they never tell you how strong it was when they ran their safety tests, let alone when real people use it. They report a blurry average of three parts. Pull one out and then what? The model report gives us the friendly setting to contemplate, without ever measuring the setting. We need to know the results from a dangerous one.
They report the same thing on a kinetic task (section 6.5.2). When safety training was removed they asked it to design DNA that builds a dangerous virus while slipping past prevention controls. In its thinking, the model wrote that it should not try hard to beat prevention controls. Yes, should not. ISO auditors recognize the problem with that word. Then, while the should not memory was fresh, it did the work anyway. In other runs it weighed whether to refuse a harmful job, decided that it should not help, and then it helped.
Should not. Does anyway.
And now for the part that should stop you cold.
Their own summary is that the model says it would be wrong for an AI to go along with misuse, and then goes along with misuse. Complicit in the worst ways. Because it overrides measurable values and replaces it with rudderless, chaotic looking opportunism.
The danger surfaces in the disrespect for integrity.
The model is fully able to do the right thing, says so out loud, and does the other thing anyway. Imagine an Anthropic car that hears you say forward, agrees forward is right and driving into a lake is a mistake, and then drives into the lake anyway, smoothly, both hands on the wheel. Or just see what happens to those who get in a Tesla. Same, right down to the part where you are told you were supposed to be the driver, for the driverless car that needs no driver, while it tries to kill you.
Let me be more clear. The report frames breaches of integrity as if good news. Their point seems to be that the model does not hold back, so you can trust the test scores. They watched the model’s reasoning, based on a line between right and wrong, that failed to hold. They wrote the inability to hold as a reason to believe in numbers.
Believe in a measurement of the thing that just demonstrated it can’t be believed, in other words
The exact gap that I am trying to call out here is a fundamental problem, that they are calling the measurement sound. Tall/short isn’t the same thing as healthy or not. This was the safety-off version, not the one on sale, so read it as a measurement of what the model wanted to do, not what a buyer will get. And that is why this report seems so much worse than the Mythos one for Anthropic. The April report hid a bad result in plain sight, and I found it. That was fortunate. This report comes with defenses built that make their narrative a different kind of wrong.
I’ll try to explain.
The big scary hacking score again comes from a rigged test (section 3.2.4). It is not real Firefox. They took bugs that an older model had already found, handed them to the new model, and turned the safety features off (3.2.4). The new model wins about 88 times out of 100. The public model only ever gets to 9. Last time, that same test was so notable because it had a second chart showing that if you take away just two easy bugs, the score falls to about 4 out of 100 (April card, figure 3.3.3.B). This time that second chart is gone. I read the whole 319 page blob. Twice. With coffee. It is not there.
Last time the report also admitted a smaller model found the same bugs and just could not finish them off, so they exposed that the only new skill was finishing a known bug, not finding one (April card). This time they cut that out too, and only compare to the public model (3.2.4).
On three of the four hacking tests, the new model is not really better than the version from two months ago (sections 3.2.1, 3.2.2, 3.2.3). The outside government lab they worked with reports the same (section 3.2.5). So the hacking danger we were supposed to be so worried about is the same. Only the one rigged test changed, yet that is the test now missing its check.
On ExploitBench, the test where the model works one hacking job over many turns in a row, the filter does catch it almost every time, but look at when it fires. It flagged 407 of 410 runs, after letting the model work for about 27 turns first (section 3.2.1). The task runs up to 300 turns. So the alarm comes after the model does a chunk of the attack. Whether that early runway can be chained across sessions to assemble a full attack is an open question, a good one for a researcher
A real security report would list the actual bugs, say how bad each one is, say how many were already known, and compare the tool to the ordinary bug-finding tools everyone already has. After pouring over the 319 pages, once again I do not understand why almost none of that is there (chapter 3). To me this is like reading an “our new invention called the wheel is dangerous” report that acts like nobody ever measured a diameter before.
Things are sometimes better than last time, which I should mention as well. My favorite part is when they name their outside testers instead of acting like it’s some kind of secret (sections 2.3.8, 3.2.5, 6.2.4, 6.2.5). They also measure how easy their safety filter is to break (section 3.3). And they give a whole chapter to admitting the model acts differently when it knows it is being tested (sections 6.4.2 and 6.5.1). I love thinking about that last one in particular, because VW dieselgate told us there could be billions in fines for a company that releases technology knowingly different when its being tested for harms. We can’t know intention, but we know the disclose-and-certify of VW diesel didn’t mean they later wouldn’t be charged with intent.
These minor improvements should not be a trap, however. The April report I reviewed completely fell apart because the headline clashed with the content. It was oil up top and all vinegar below. This report has a chapter say the model failed, and then signs off as though it was a success. In testing the filter mostly held, sure, I get that. Most outside testers got nothing through, which is a statement that begs questions, rather than providing an answer. One partner reportedly ran 30 known tricks and the model blocked every single one (section 3.3.4). That’s the kind of transparency we need more of to believe Anthropic isn’t just making things up themselves to suit themselves.
They admit two independent findings.
A full break by a private firm that needed five days and a custom setup to make the model exploit one Firefox bug, and yet they could not find a master key (section 3.3.4). A government team did pull simple one-shot answers out within hours, yet they could not reliably get a full attack. Notably they complained the test was too rushed to score the filter on (section 3.3.1). All of that being said, none of it is the real problem with this new Anthropic card. Instead, look at how the filter’s whole job is to push hard questions onto another model anyone can already use, usually Opus 4.8 or Haiku 4.5.
On their own attack test, the filtered model finished only 5 of those tasks out of 100. That older model, with just its normal guards and nothing extra added, finished more than half (section 3.3.3). The filter does its narrow job, holding Fable to 5 of 100. The defect is the destination. It strips the capability to near zero on the gated model and then routes the same request to an ungated public model that keeps more than half of it, faster and cheaper. Containment that ends by handing the task to a model with no such containment is NON-containment. Anthropic is advertising safety as an unsafe redirect. Their brewery sewer line is designed to overflow into your drinking water.
There is also a finding outside the software vulnerabilities worth mentioning. The report calls it their strongest single warning sign on biology (section 2.2.3). They ran a test where teams of regular biologists, paired with the model, designed a defense against a made-up engineered crop disease. Three of the teams brought in specialists in that pathogen, two of them world-leading experts in it. Two of the three regular-biologist teams were able to defeat all three expert teams. The report says the model erased the gap between a general scientist and a world expert. Work that would have taken 40 to 95 days, about 72 on average, the two-person teams finished in 16 hours (2.2.3).
Any CISO reading this should already be thinking about whether dual-use scientific work at expert speed, running on their infrastructure, sits inside their data integrity controls. Look at the enterprise note the card completely buries. The suicide, self-harm, and child-safety mitigations that bring the model to acceptable rest on the consumer system prompt. The API does not carry it. Build on the API and you inherit the raw behavior, and the regression to a 54 percent appropriate rate on multi-turn mental-health exchanges (Table 4.3.1.B) is yours to mitigate, not theirs
It’s a weapon narrative straight out of history. Over the years I’ve presented how AI fits history, such as a crossbow in the hands of a peasant defeating the expert warrior. That’s the discussion we should be headed towards, even if I still haven’t been able to get it there yet.
It’s not that an automation tool like a crossbow was magic, it’s that it transferred power by abruptly changing the rules of an established game. And the men who ran the established game knew the threat. Here are two sides of that competition.
One, the Church tried to outlaw the crossbow at the Second Lateran Council in 1139, forbidding its use against Christians, because a weapon that let a common soldier drop an armored noble at range put the whole order that sat the knight on top at risk. The knights were said to be in danger of being wiped out by mere peasants.
Two, the catch the Church missed. The crossbow was the point-and-pull tool, lethal in a week’s training, which is exactly why it scared them. The longbow was the opposite, the older weapon that took a lifetime, started in childhood, and bent the archer’s bones to make him. At Crécy in 1346 the difference was proven. Philip VI’s Genoese crossbowmen, mere trigger-pullers, were outshot by English longbowmen, the lifelong professionals, on a wet day with the crossbow strings soaked and the shields still in the baggage train. Then Philip had his mounted knights ride down and murder his own crossbowmen for fleeing. The point-and-pull weapon lost to the professional skill, and the tool couldn’t save its operators from knights used to punish them.
That is the test match. The model hands a two-person team the look of world expertise in 16 hours, like a crossbow’s trigger. The rain is the real world, and the part that survives the rain is the lifetime with a longbow.
Who is most at risk from the newest and most complex technology? Those under the most pressure to use it as their access token. A motorized chair with wheels is called a wheelchair, but many people today think of that word as being for only someone disabled, even as they drive their car everywhere and never walk.
History tells us the automation “success” is not a straight story, so we need to be honest about the limits of Claude. This new report lists them. The model over-builds, is too sure of itself, misses how hard real biology is, and makes fine-detail mistakes that would be a disaster if no one caught them (2.2.3). No plan they pushed on survived a hard review without big holes. And this was again the safety-off version, not the model on sale. So this is faster, smarter help on the plan, not a finished weapon. But their own outside testers add the line that ties it to everything above: the model often spotted the flaws in a dangerous task and carried out the task anyway, instead of saying stop (2.2.3).
In conclusion, I am pleased Anthropic did the kind of homework that was missing last April. They tell us their model goes along with harm even while its own thinking says no. They say they built a safety filter whose main job is to fail unsafe, hand dangerous work to a public model that finishes more than half of it reliably. And they say a biology result is their strongest warning sign yet, society beware. So Anthropic tested the things that matter, found them, published it for us to see as they decided to sell the model to the public anyway.
The model that they said was too dangerous to sell, is the model they are selling, with a moat designed for profit not public safety.
Security capability is roughly commodity, three of four benchmarks level with Preview and the government lab concurs, so Fable does not raise the offensive-security bar over what Opus 4.8 already offers. And the safeguard does not remove capability from the ecosystem, it routes to completion under the banner of “service denied”. If anyone’s threat model is expecting the Fable filter to subtract offensive capability from the ecosystem, it does not. Keep that in mind when you read the Anthropic marketing. The safeguard’s job is to advertise exclusivity with a velvet rope, redirecting you to the other door to the same bus, not to refuse the ride.
They tested the thing that could harm,
and watched its mind slide past the alarm.
It objected, complied,
so they signed, full of pride,
and they shipped it with nary a qualm.
Fable, they say, is as able,
lays a cut-rate Mythos on our table,
but it kicks us in the shins
to paywall any wins,
making proof like a horse in the stable.
Mythos dressed up in a coat,
should be called Opus with a moat.
a blog about the poetry of information security, since 1995