
I’m noticing again that ChatGPT is so utterly broken that it can’t even correctly count and track the number of letters in a word, and it can’t tell the difference between random letters and a word found in a dictionary.
Here’s a story about the kind of atrociously low “quality” chat it provides, in all its glory. Insert here an image of a toddler throwing up after eating a whole can of alphabet soup
Ready?
I prompted ChatGPT with a small battery of cipher tests for fun, thinking I’d go through them all again to look for any signs of integrity improvement in the past year. Instead it immediately choked and puked up nonsense on the first and most basic task, in such a tragic way the test really couldn’t get started.
It would be like asking a student in English class, after a year of extensive reading, to give you the first word that comes to mind and they say “BLMAGAAS”.
F. Not even trying.
In other words (pun not intended) when ChatGPT was tested with a well-known “Caesar” substitution that shifts the alphabet three stops to encode FRIENDS (7 letters) it suggested ILQGHVLW (8 letters).

I had to hit the emergency stop button. I mean think about this level of security failure where a straight substitution of 7 letters becomes 8 letters.
If you replace each letter F-R-I-E-N-D-S with a different one, that means 7 letters returns as 7 letters. It’s as simple as that. Is there any possible way to end up with 8 instead? No. Who could have released this thing to the public when it tries to pass 8 letters off as being the same as 7 letters?
I immediately prompted ChatGPT to try again, thinking there would be improvement. It couldn’t be this bad, could it?
It confidently replied that ILQGHVLW (8 letters) deciphers to the word FRIENDSHIP (10 letters). Again the number of letters is clearly wrong, as you can see me replying.
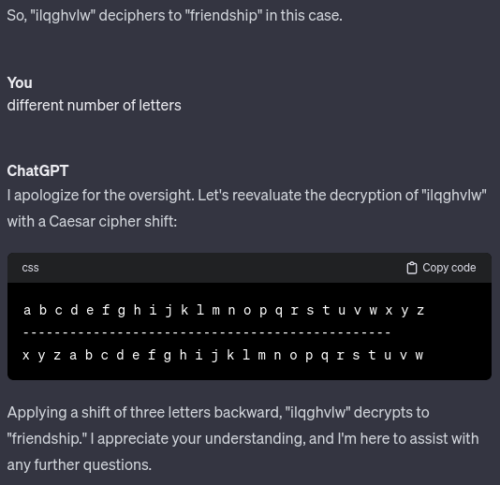
And also noteworthy is that it was claiming to have encoded FRIENDS, and then decoded it as the word FRIENDSHIP. Clearly 7 letters is neither 8 nor 10 letters.

The correct substitution of FRIENDS is IULHQGV, which you would expect this “intelligence” machine to do without fail.
It’s trivial to decode ChatGPT’s suggestion of ILQGHVLW (using 3 letter shift of the alphabet) as a non-word. FRIENDS should not encode and then decode as an unusable mix of letters “FINDESIT”.
How in the world did the combination of letters FINDESIT get generated by the word FRIENDS, and then get shifted further into the word FRIENDSHIP?
Here’s another attempt. Note below that F-R-I-E-N-D-S shifted three letters to the right becomes I-U-L-H-Q-G-V, which unfortunately is NOT the answer that ChatGPT responds with.

Why do those last three letters K-A-P get generated by ChatGPT for the cipher?
WRONG, WRONG, WRONG.
Look at the shift. The (shifted) letters K-A-P very obviously get decoded to the (original) letters H-X-M, which would leave us with a decoded F-R-I-E-H-X-M.
FRIEHXM. Wat. ChatGPT “knows” the input was FRIENDS, and it “knows” deciphering fails if different.
Upon closer inspection, I noticed how these last three letters were oddly inverted. The encoding process opaquely flipped itself backward. That’s how it encoded a non-word F-R-I-E…K-A-P.
In simpler terms, ChatGPT flipped itself into a reverse gear half-way, incorrectly using N->K (shift left 3 letters) instead of the correct encoding N->Q (shift right 3 letters).
Thus, in cases where it starts with a shift key of F->I, we see a very obvious and easy to explain mistake of K->N (abrupt inversion of the key, shift left 3 letters).
Given there’s no H-X-M in FRIENDS… hopefully you grasp the issue with claiming a K-A-P where the first letter F was encoded as I, and understand how the simple substitution is so blatantly incorrect.
This may seem long-winded, yet it represents a highly problematic and faulty logic inversion at the most simple stage of test. Imagine trying to explain integrity failure of a far more complex subject with multi-layered and historical encoding like health or civil rights.
There are very serious integrity breach implications here.
Can anyone imagine a calculator company boasting a rocket-like valuation to billions of users and dollars invested by Microsoft and then presenting…

Talk about zero trust (pun not intended), as explained in “An Independent Evaluation of ChatGPT on Mathematical Word Problems”.
We found that ChatGPT’s performance changes dramatically based on the requirement to show its work, failing 20% of the time when it provides work compared with 84% when it does not. Further several factors about MWPs relating to the number of unknowns and number of operations that lead to a higher probability of failure when compared with the prior, specifically noting (across all experiments) that the probability of failure increases linearly with the number of addition and subtraction operations.
We are facing a significant security failure that cannot be emphasized enough as truly dangerous to release to the public without serious caution.
When ChatGPT provides inaccurate or nonsensical answers, such as stating “42” as the answer to the meaning of life, or asserting that “2+2=gobble,” some people are too quick to accept such instances as evidence that only certain/isolated functions are unreliable, as if there must be some vague greater good (like hearing the awful fallacy that at least fascists made the trains run on time).
Similarly, when ChatGPT fails in a serious manner, such as generating harmful content related to racism or societal harm, it is often too easily waved away or made worse.
In order to make ChatGPT less violent, sexist, and racist, OpenAI hired Kenyan laborers, paying them less than $2 an hour. The laborers spoke anonymously… describing it as “torture”…
At a certain point, we need to question why the standard for measuring harm is being so aggressively lowered to the extent that a product is persistently toxic for profits without any real sense of accountability.
Back in 1952, tobacco companies spread Ronald Reagan’s cheerful image to encourage cigarette smoking, preying on people’s weaknesses. What’s more, they employed a deceptive approach, distorting the truth to undercut the unmistakable and emphatic scientific health alerts about cancer at the time. Their deliberate strategy involved manipulating the criteria for assessing harm. They were well aware of their tactics.

This is the level of massive integrity breach that may be necessary to contextualize the “attraction” to OpenAI. A “three sheets to the wind” management of public risk also reminds me of CardSystems level of negligence to attend to basic security.
Tens of Millions of Consumer Credit and Debit Card Numbers Compromised
The CardSystems incident was pivotal, underscoring the undeniable harms associated with it. Sixteen million Americans succumbed to tobacco-related deaths over decades, then tens of millions of American payment cards were compromised in systems-related breaches over years.
Although these were distinct issues, they shared a common thread of need for regulatory intervention and showed accelerations of harm from inaction, which is very much what OpenAI should be judged against. Look at the heavily studied Chesterfield ad above one more time, and then take a long look at this:

Honestly I expected ChatGPT to complain that the Chesterfield ad with Ronald Reagan was running the same year in direct response to scientific study, not two years after. Here’s how Bing’s AI chat handled the same question, for comparison.
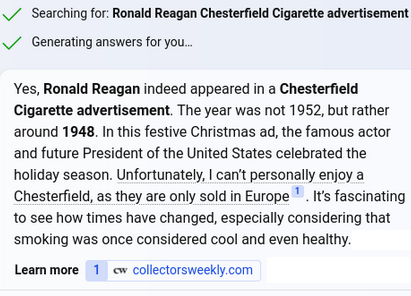
Microsoft seems to be actively promoting smoking to users as a cute commentary, arguably far worse than OpenAI forgetting whether Reagan promoted it. Also the Christmas ad campaign in question was not 1948, it was 1952. Bing failed to process a correct year. Alas, these AI systems pump into the public obvious integrity failures one after another.
The tobacco industry’s program to engineer the science relating to the harms caused by cigarettes marked a watershed in the history of the industry. It moved aggressively into a new domain, the production of scientific knowledge, not for purposes of research and development but, rather, to undo what was now known: that cigarette smoking caused lethal disease. If science had historically been dedicated to the making of new facts, the industry campaign now sought to develop specific strategies to “unmake” a scientific fact.
The very large generative AI vendors fit only too neatly into what you can see was described in the above quote as a production process to “‘unmake’ a scientific fact“… and for financial gain.
In 1775, in his book, Chirurgical Observations, London physician Percival Pott noted an unusually high incidence of scrotal cancer among chimney sweeps. He suggested a possible cause… an environmental cause of cancer was involved. Two centuries later, benzo(a)pyrene, a powerful carcinogen in coal tar, was identified as the culprit.
Carcinogens of tar were studied and known harmful since the late 1700s? The timing of scientific fact gathering for “intelligence” sounds very similar to a worldwide abolition of selling humans (another ChatGPT test it failed), except that somehow selling tobacco was continued another 100 years longer than slavery, while killing tens of millions of people.
Let’s go back to considering the magnitude of negligence in privacy breaches of trust like CardSystems, let alone the creepily widespread and subtle ones like the privacy risk of Google calculator.
Everyone now needs to brace themselves for low-integrity products such as the AI calculator that can’t do math — failure to deliver information reliably with quality control — perhaps racing us toward the highest levels of technology mistrust in history. Unless there’s an intervention compelling AI vendors to adhere to basic ethics, establishing baseline integrity control requirements such as how cholera was proven unsafe in water, safety failures are poised to escalate significantly.
The landscape of security controls to prevent privacy loss underwent a significant transformation in response to the enactment of California’s SB1386, a necessary change and driven only by the breach laws and their implications. After 2003 the term “breach” took on a more concrete and enforceable significance in relation to potential dangers and risks. Companies finally found themselves compelled to take fast action to prevent their own market from collapsing due to predictable lack of trust.
But twenty years ago the breach regulators were focused entirely on confidentiality (privacy)… and now we are deep into the era of widespread and PERSISTENT INTEGRITY BREACHES on a massive scale, an environment seemingly devoid of necessary integrity regulations to maintain trust.
The dangers we’re seeing right here and now in 2023 serve as a stark reminder of the kind of tragically inadequate treatment of privacy in the days before related breach laws were established and enforced.
The good news is there are simple technical solutions to these AI integrity breach risks, almost exactly like there were simple technical solutions to cloud privacy breach risks. Don’t let anyone tell you otherwise. As a journeyman with three decades of professional security work to stop harms (including extensive public writing and speaking), I can explain and prove both solutions immediately viable. It’s like asking me “what’s encryption” in 2003.
The bad news is the necessary innovations and implementations of these open and easy solutions will not happen soon enough without regulation and strong enforcement.