Ok, so if the 2013 Hyperloop “invention” is actually a 150-year old concept doomed to obvious failure, what about SpaceX playing obnoxious PR with boastful claims since 2011 that it’s the first to figure out reuseable rockets?
SpaceX Makes History With First-Ever Recycled Rocket
Wat. I mean really. Wat.
SpaceX becomes first to re-fly used rocket
Oh FFS. Who writes this stuff?
How spaceX successfully designed the world’s first reusable rocket
No. No. And… Nope. The whole history of SpaceX seems to be littered with ugly disinformation.
SpaceX Unveils Plan for World’s First Fully Reusable Rocket
It’s not even remotely true that SpaceX would be first, yet it still floats around as an unchallenged headline.
Apparently they’ve just been throwing more money at propaganda than anyone before, with more marketing and attention seeking fiction to generate funding, not actually solving much else by comparison.
Boeing’s Reusable Aerodynamic Space Vehicle (RASV) developed in the 1970s would have taken off and landed horizontally, like an aircraft, and would have featured the rapid turnaround, ease of maintenance, economy of operation, and abort capability found in the commercial airplane industry. RASV would launch several dozens (if not hundreds) of times, would be able to fly again shortly after landing (in two weeks or even in 24 hours or less), and would use small flight and operational teams.
What made the Clipper Graham [DC-X] unique was that it combined the development of rocket-powered single-stageto-orbit transport with aircraft-like operations and a program approach that featured a modest budget, an accelerated timetable, a small managerial team, and minimal paperwork. No other single-stage-to-orbit project had been run before in this “faster, cheaper, smaller” fashion. Also, the Graham Clipper was the first rocket-powered vehicle, experimental or not, to demonstrate aircraft-like operations.
A full-scale pre-production orbital prototype was planned (DC-Y), meant to be followed by the production DC-1.
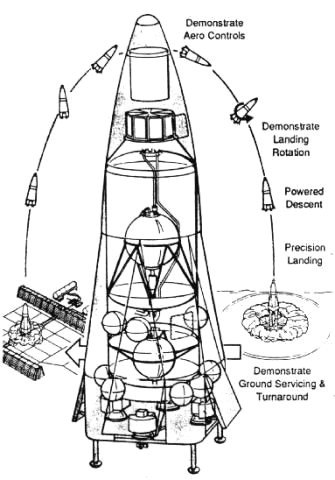
Allegedly when SpaceX was created, Elon Musk told Jess Sponable that it was to continue the prior DC-X project success. Sponable had in fact participated in multiple reusable rocket vehicle projects at USAF, DARPA and elsewhere including the X-33 and X-34, just to be clear about the many priors to SpaceX. The point is that a disinformation tweet from Elon Musk might generate millions of views instantly and headlines in papers, all poisoning history, yet an interview a year ago with Jess about real facts has only 115 views so far…
…[DC-X] did the rotation maneuver that SpaceX did so dramatically in recent years in 1996 or 1995… a lot of [our DC-X reusable rocket] data was provided to Elon Musk at SpaceX…
While DC-X was by far the most famous in the mid 1990s — literally entered into a space hall of fame — somehow SpaceX has been allowed to lie. It constantly spread misleading information, without any corrections or shame, as if it was initiating the same concepts and maneuvers at least two decades late in the 2010s.
The first flight of the DC-X from the “Clipper-Site” was on August 18, 1993, at Northrup Strip, now known as White Sands Space Harbor, on White Sands Missile Range, New Mexico. The team actually built a mini-spaceport along the edge of the Northrop Strip. It incorporated all the functions of an operational spaceport. It was a breathtaking vertical launch that left the spectators in attendance in awe. “The DC-X launched vertically, hovered in mid-air at 150 feet, and began to move sideways at a dogtrot. After traveling 350 feet, the onboard global-positioning satellite unit indicated that the DC-X was directly over its landing point. The spacecraft stopped mid-air again and, as the engines throttled back, began its successful vertical landing. Just like Buck Rogers,” said an article from the Ada Joint Program Office of the U.S. Government.
Politics killed the DC-X reusable rocket for various reasons. The concept went dormant until after President Bush mistakenly withdrew from the ABMT and then the idea was restarted in a new arms race… driving DoD innovations into a highly unaccountable private company that has become known for its failures: SpaceX.
Awkward.
Apparently everything Musk does turns out a giant origination scam, stealing ideas and public money to fraudulently redirect investors away from real engineering into his political pockets.